













")

 – Glass Blue|Unisoc T606 Octa Core Processor| 90 Hz Refresh Price|Aspect Fingerprint Sensor|13MP Twin AI Digicam| 5000 mAh Battery| Upto 6GB Expandable RAM")

| 32MP Selfie + 50MP Foremost Digital camera| 90Hz Dot-in Show with Dynamic Port & Twin Audio system with DTS| 5000mAh Battery |18W Kind-C| Helio G85 Processor")


















Use RAGAs framework with hyperparameter optimisation to spice up the standard of your RAG system.

TL;DR
Should you develop a RAG system you could select between totally different design choices. That is the place the ragas library may also help you by producing artificial analysis information with solutions grounded in your paperwork. This makes attainable the rigorous analysis of a RAG system with the basic cut up between practice/validation/take a look at units. Because the outcome the standard of your RAG system will get an enormous increase.
Introduction
The event of Retrieval Augmented Era (RAG) system in observe includes taking a whole lot of selections which can be consequential for its final high quality, i.e.: about textual content splitter, chunk dimension, overlap dimension, embedding mannequin, metadata to retailer, distance metric for semantic search, top-k to rerank, reranker mannequin, top-k to context, immediate engineering, and many others.
Actuality: Typically such selections should not grounded in methodologically sound analysis practices, however moderately pushed by ad-hoc judgments of builders and product homeowners, usually dealing with deadlines.
Gold Customary: In distinction the rigorous analysis of RAG system ought to contain:
- a big analysis set, in order that efficiency metrics are estimated with low confidence intervals
- various questions in an analysis set
- solutions particular to the inner paperwork
- separate analysis of retrieval and technology
- analysis of the RAG because the complete
- practice/validation/take a look at cut up to make sure good generalisation potential
- hyperparameter optimisation
Most RAG techniques are NOT evaluated rigorously as much as the Gold Customary on account of lack of analysis units with solutions grounded within the non-public paperwork!
The generic Massive Language Mannequin (LLM) benchmarks (GLUE, SuperGlue, MMLU, BIG-Bench, HELM, …) should not of a lot relevance to guage RAGs because the essence of RAGs is to extract data from inner paperwork unknown to LLMs. Should you insist to make use of LLM benchmarks for RAG system analysis one route could be to pick out the duty particular to your area, and quantify the worth added of the RAG system on high of naked bones LLM for this chosen job.
The choice to generic LLM benchmarks is to create human annotated take a look at units based mostly on inner paperwork, in order that the questions require entry to those inner paperwork with a view to reply them appropriately. Usually such an answer is prohibitively costly most often. As well as, outsourcing annotation could also be problematic for inner paperwork, as they’re delicate or include non-public data and may’t be shared with outdoors events.
Right here comes the RAGAs framework (Retrieval Augmented Era Evaluation) [1] for reference-free RAG analysis, with Python implementation made obtainable in ragas bundle:
pip set up ragas
It supplies important instruments for rigorous RAG analysis:
- technology of artificial analysis units
- metrics specialised for RAG analysis
- immediate adaptation to take care of non-English languages
- integration with LangChain and Llama-Index
Artificial Analysis Units
The LLMs fans, me included, are likely to recommend utilizing LLM as an answer to many issues. Right here it means:
LLMs should not autonomous, however could also be helpful. RAGAs employs LLMs to generate artificial analysis units to guage RAG techniques.
RAGAs framework follows up on on the thought of Evol-Instruct framework, which makes use of LLM to generate a various set of instruction information (i.e. Query — Reply pairs, QA) within the evolutionary course of.

In Evol-Instruct framework LLM begins with an preliminary set of easy directions, and regularly rewrites them into extra advanced directions, creating a various instruction information because the outcome. Can Xu et al [2] argue that gradual, incremental, evolution instruction information is extremely efficient in producing prime quality outcomes. In RAGAs framework instruction information generated and advanced by LLM are grounded in obtainable paperwork. The ragas library presently implements three various kinds of instruction information evolution by depth ranging from the easy query:
- Reasoning: Rewrite the query to extend the necessity for reasoning.
- Conditioning: Rewrite the query to introduce a conditional component.
- Multi-Context: Rewrite the query to requires many paperwork or chunks to reply it.
As well as ragas library additionally supplies the choice to generate conversations. Now let’s see ragas in observe.
Examples of Query Evolutions
We’ll use the Wikipedia web page on Massive Language Fashions [3] because the supply doc for ragas library to generate query — floor fact pairs, one for every evolution kind obtainable.
To run the code: You may comply with the code snippets within the article or entry the pocket book with all of the associated code on Github to run on Colab or domestically:
colab-demos/rags/evaluate-rags-rigorously-or-perish.ipynb at major · gox6/colab-demos
# Putting in Python packages & hiding
!pip set up --quiet
chromadb
datasets
langchain
langchain_chroma
optuna
plotly
polars
ragas
1> /dev/null
# Importing the packages
from functools import cut back
import json
import os
import requests
import warnings
import chromadb
from chromadb.api.fashions.Assortment import Assortment as ChromaCollection
from datasets import load_dataset, Dataset
from getpass import getpass
from langchain_chroma import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.runnables.base import RunnableSequence
from langchain_community.document_loaders import WebBaseLoader, PolarsDataFrameLoader
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from operator import itemgetter
import optuna
import pandas as pd
import plotly.categorical as px
import polars as pl
from ragas import consider
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
answer_correctness
)
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import easy, reasoning, multi_context, conditional
# Offering api key for OPENAI
OPENAI_API_KEY = getpass("OPENAI_API_KEY")
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
# Inspecting query evolution varieties evailable in ragas library
urls = ["https://en.wikipedia.org/wiki/Large_language_model"]
wikis_loader = WebBaseLoader(urls)
wikis = wikis_loader.load()
llm = ChatOpenAI(mannequin="gpt-3.5-turbo")
generator_llm = llm
critic_llm = llm
embeddings = OpenAIEmbeddings()py
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# Change ensuing query kind distribution
list_of_distributions = [{simple: 1},
{reasoning: 1},
{multi_context: 1},
{conditional: 1}]
# This step COSTS $$$ ...
question_evolution_types = record(
map(lambda x: generator.generate_with_langchain_docs(wikis, 1, x),
list_of_distributions)
)
# Displaying examples
examples = cut back(lambda x, y: pd.concat([x, y], axis=0),
[x.to_pandas() for x in question_evolution_types])
examples = examples.loc[:, ["evolution_type", "question", "ground_truth"]]
examples
Working the above code I obtained the next artificial query — reply pairs based mostly on the aforementioned Wikipedia web page [3].
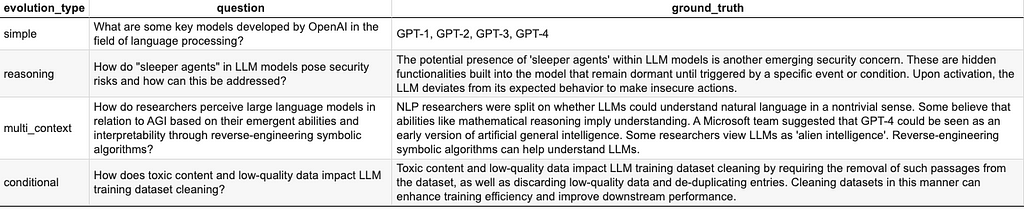
The outcomes offered within the Desk 1 appear very interesting, not less than to me. The easy evolution performs very effectively. Within the case of the reasoning evolution the primary a part of query is answered completely, however the second half is left unanswered. Inspecting the Wikipedia web page [3] it’s evident that there is no such thing as a reply to the second a part of the query within the precise doc, so it will also be interpreted because the restraint from hallucinations, a great factor in itself. The multi-context question-answer pair appears excellent. The conditional evolution kind is appropriate if we have a look at the question-answer pair. A technique of taking a look at these outcomes is that there’s at all times house for higher immediate engineering which can be behind evolutions. One other manner is to make use of higher LLMs, particularly for the critic function as is the default within the ragas library.
Metrics
The ragas library is ready to not solely generate the artificial analysis units, but in addition supplies us with built-in metrics for component-wise analysis in addition to end-to-end analysis of RAGs.
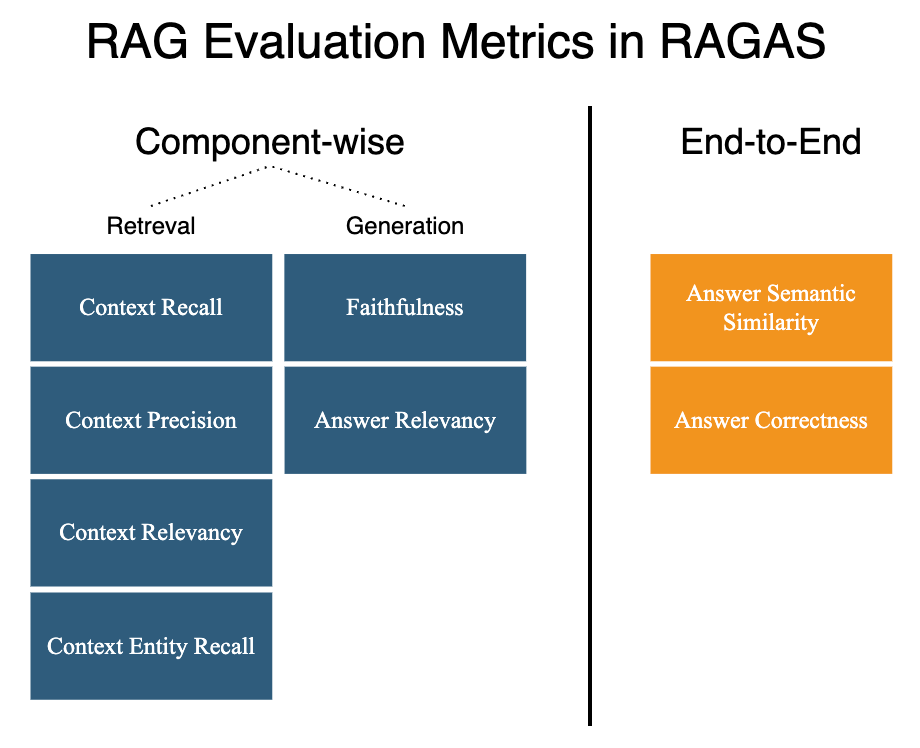
As of this writing RAGAS supplies out-of-the-box eight metrics for RAG analysis, see Image 2, and sure new ones shall be added sooner or later. Usually you’re about to decide on the metrics best suited on your use case. Nevertheless, I like to recommend to pick out the one most necessary metric, i.e.:
Reply Correctness — the end-to-end metric with scores between 0 and 1, the upper the higher, measuring the accuracy of the generated reply as in comparison with the bottom fact.
Specializing in the one end-to-end metric helps to begin the optimisation of your RAG system as quick as attainable. When you obtain some enhancements in high quality you may have a look at component-wise metrics, specializing in an important one for every RAG part:
Faithfulness — the technology metric with scores between 0 and 1, the upper the higher, measuring the factual consistency of the generated reply relative to the offered context. It’s about grounding the generated reply as a lot as attainable within the offered context, and by doing so stop hallucinations.
Context Relevance — the retrieval metric with scores between 0 and 1, the upper the higher, measuring the relevancy of retrieved context relative to the query.
RAG Manufacturing unit
OK, so we have now a RAG prepared for optimisation… not so quick, this isn’t sufficient. To optimise RAG we’d like the manufacturing unit operate to generate RAG chains with given set of RAG hyperparameters. Right here we outline this manufacturing unit operate in 2 steps:
Step 1: A operate to retailer paperwork within the vector database.
# Defining a operate to get doc assortment from vector db with given hyperparemeters
# The operate embeds the paperwork provided that assortment is lacking
# This improvement model as for manufacturing one would moderately implement doc stage verify
def get_vectordb_collection(chroma_client,
paperwork,
embedding_model="text-embedding-ada-002",
chunk_size=None, overlap_size=0) -> ChromaCollection:
if chunk_size is None:
collection_name = "full_text"
docs_pp = paperwork
else:
collection_name = f"{embedding_model}_chunk{chunk_size}_overlap{overlap_size}"
text_splitter = CharacterTextSplitter(
separator=".",
chunk_size=chunk_size,
chunk_overlap=overlap_size,
length_function=len,
is_separator_regex=False,
)
docs_pp = text_splitter.transform_documents(paperwork)
embedding = OpenAIEmbeddings(mannequin=embedding_model)
langchain_chroma = Chroma(consumer=chroma_client,
collection_name=collection_name,
embedding_function=embedding,
)
existing_collections = [collection.name for collection in chroma_client.list_collections()]
if chroma_client.get_collection(collection_name).rely() == 0:
langchain_chroma.from_documents(collection_name=collection_name,
paperwork=docs_pp,
embedding=embedding)
return langchain_chroma
Step 2: A operate to generate RAG in LangChain with doc assortment, or the correct RAG manufacturing unit operate.
# Defininig a operate to get a easy RAG as Langchain chain with given hyperparemeters
# RAG returns additionally the context paperwork retrieved for analysis functions in RAGAs
def get_chain(chroma_client,
paperwork,
embedding_model="text-embedding-ada-002",
llm_model="gpt-3.5-turbo",
chunk_size=None,
overlap_size=0,
top_k=4,
lambda_mult=0.25) -> RunnableSequence:
vectordb_collection = get_vectordb_collection(chroma_client=chroma_client,
paperwork=paperwork,
embedding_model=embedding_model,
chunk_size=chunk_size,
overlap_size=overlap_size)
retriever = vectordb_collection.as_retriever(top_k=top_k, lambda_mult=lambda_mult)
template = """Reply the query based mostly solely on the next context.
If the context doesn't include entities current within the query say you don't know.
{context}
Query: {query}
"""
immediate = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(mannequin=llm_model)
def format_docs(docs):
return "nn".be a part of([doc.page_content for doc in docs])
chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| immediate
| llm
| StrOutputParser()
)
chain_with_context_and_ground_truth = RunnableParallel(
context=itemgetter("query") | retriever,
query=itemgetter("query"),
ground_truth=itemgetter("ground_truth"),
).assign(reply=chain_from_docs)
return chain_with_context_and_ground_truth
The previous operate get_vectordb_collection is integrated into the latter operate get_chain, which generates our RAG chain for given set of parameters, i.e: embedding_model, llm_model, chunk_size, overlap_size, top_k, lambda_mult. With our manufacturing unit operate we’re simply scratching the floor of prospects what hyperparmeters of our RAG system we optimise. Observe additionally that RAG chain would require 2 arguments: query and ground_truth, the place the latter is simply handed via the RAG chain as it’s required for analysis utilizing RAGAs.
# Establishing a ChromaDB consumer
chroma_client = chromadb.EphemeralClient()
# Testing full textual content rag
with warnings.catch_warnings():
rag_prototype = get_chain(chroma_client=chroma_client,
paperwork=information,
chunk_size=1000,
overlap_size=200)
rag_prototype.invoke({"query": 'What occurred in Minneapolis to the bridge?',
"ground_truth": "x"})["answer"]
RAG Analysis
To guage our RAG we are going to use the varied dataset of stories articles from CNN and Each day Mail, which is obtainable on Hugging Face [4]. Most articles on this dataset are under 1000 phrases. As well as we are going to use the tiny extract from the dataset of simply 100 information articles. That is all achieved to restrict the prices and time wanted to run the demo.
# Getting the tiny extract of CCN Each day Mail dataset
synthetic_evaluation_set_url = "https://gist.github.com/gox6/0858a1ae2d6e3642aa132674650f9c76/uncooked/synthetic-evaluation-set-cnn-daily-mail.csv"
synthetic_evaluation_set_pl = pl.read_csv(synthetic_evaluation_set_url, separator=",").drop("index")
# Practice/take a look at cut up
# We want not less than 2 units: practice and take a look at for RAG optimization.
shuffled = synthetic_evaluation_set_pl.pattern(fraction=1,
shuffle=True,
seed=6)
test_fraction = 0.5
test_n = spherical(len(synthetic_evaluation_set_pl) * test_fraction)
practice, take a look at = (shuffled.head(-test_n),
shuffled.head( test_n))
As we are going to take into account many various RAG prototypes past the one outline above we’d like a operate to gather solutions generated by the RAG on our artificial analysis set:
# We create the helper operate to generate the RAG ansers along with Floor Fact based mostly on artificial analysis set
# The dataset for RAGAS analysis ought to include the columns: query, reply, ground_truth, contexts
# RAGAs expects the info in Huggingface Dataset format
def generate_rag_answers_for_synthetic_questions(chain,
synthetic_evaluation_set) -> pl.DataFrame:
df = pl.DataFrame()
for row in synthetic_evaluation_set.iter_rows(named=True):
rag_output = chain.invoke({"query": row["question"],
"ground_truth": row["ground_truth"]})
rag_output["contexts"] = [doc.page_content for doc
in rag_output["context"]]
del rag_output["context"]
rag_output_pp = {okay: [v] for okay, v in rag_output.objects()}
df = pl.concat([df, pl.DataFrame(rag_output_pp)], how="vertical")
return df
RAG Optimisation with RAGAs and Optuna
First, it’s price emphasising that the correct optimisation of RAG system ought to contain world optimisation, the place all parameters are optimised directly, in distinction to the sequential or grasping method, the place parameters are optimised one after the other. The sequential method ignores the truth that there may be interactions between the parameters, which may end up in sub-optimal resolution.
Now ultimately we’re able to optimise our RAG system. We’ll use hyperparameter optimisation framework Optuna. To this finish we outline the target operate for the Optuna’s research specifying the allowed hyperparameter house in addition to computing the analysis metric, see the code under:
def goal(trial):
embedding_model = trial.suggest_categorical(identify="embedding_model",
selections=["text-embedding-ada-002", 'text-embedding-3-small'])
chunk_size = trial.suggest_int(identify="chunk_size",
low=500,
excessive=1000,
step=100)
overlap_size = trial.suggest_int(identify="overlap_size",
low=100,
excessive=400,
step=50)
top_k = trial.suggest_int(identify="top_k",
low=1,
excessive=10,
step=1)
challenger_chain = get_chain(chroma_client,
information,
embedding_model=embedding_model,
llm_model="gpt-3.5-turbo",
chunk_size=chunk_size,
overlap_size= overlap_size ,
top_k=top_k,
lambda_mult=0.25)
challenger_answers_pl = generate_rag_answers_for_synthetic_questions(challenger_chain , practice)
challenger_answers_hf = Dataset.from_pandas(challenger_answers_pl.to_pandas())
challenger_result = consider(challenger_answers_hf,
metrics=[answer_correctness],
)
return challenger_result['answer_correctness']
Lastly, having the target operate we outline and run the research to optimise our RAG system in Optuna. It’s price noting that we will add to the research our educated guesses of hyperparameters with the strategy enqueue_trial, in addition to restrict the research by time or variety of trials, see the Optuna’s docs for extra ideas.
sampler = optuna.samplers.TPESampler(seed=6)
research = optuna.create_study(study_name="RAG Optimisation",
path="maximize",
sampler=sampler)
research.set_metric_names(['answer_correctness'])
educated_guess = {"embedding_model": "text-embedding-3-small",
"chunk_size": 1000,
"overlap_size": 200,
"top_k": 3}
research.enqueue_trial(educated_guess)
print(f"Sampler is {research.sampler.__class__.__name__}")
research.optimize(goal, timeout=180)
In our research the educated guess wasn’t confirmed, however I’m certain that with rigorous method because the one proposed above it’s going to get higher.
Finest trial with answer_correctness: 0.700130617593832
Hyper-parameters for the most effective trial: {'embedding_model': 'text-embedding-ada-002', 'chunk_size': 700, 'overlap_size': 400, 'top_k': 9}
Limitations of RAGAs
After experimenting with ragas library to synthesise evaluations units and to guage RAGs I’ve some caveats:
- The query could include the reply.
- The bottom-truth is simply the literal excerpt from the doc.
- Points with RateLimitError in addition to community overflows on Colab.
- Constructed-in evolutions are few and there’s no straightforward manner so as to add new, ones.
- There’s room for enhancements in documentation.
The primary 2 caveats are high quality associated. The basis reason for them could also be within the LLM used, and clearly GPT-4 offers higher outcomes than GPT-3.5-Turbo. On the similar time evidently this could possibly be improved by some immediate engineering for evolutions used to generate artificial analysis units.
As for points with rate-limiting and community overflows it’s advisable to make use of: 1) checkpointing throughout technology of artificial analysis units to forestall lack of of created information, and a pair of) exponential backoff to ensure you full the entire job.
Lastly and most significantly, extra built-in evolutions could be welcome addition for the ragas bundle. To not point out the potential of creating customized evolutions extra simply.
Different Helpful Options of RAGAs
- Customized Prompts. The ragas bundle supplies you with the choice to vary the prompts used within the offered abstractions. The instance of customized prompts for metrics within the analysis job is described within the docs. Under I exploit customized prompts for modifying evolutions to mitigate high quality points.
- Automated Language Adaptation. RAGAs has you lined for non-English languages. It has an awesome characteristic referred to as computerized language adaptation supporting RAG analysis within the languages aside from English, see the docs for extra data.
Conclusions
Regardless of RAGAs limitations do NOT miss an important factor:
RAGAs is already very useful gizmo regardless of its younger age. It allows technology of artificial analysis set for rigorous RAG analysis, a essential facet for profitable RAG improvement.
Should you loved studying this text take into account serving to me put it on the market to the opposite readers, please clap or reply. I invite You to have a look at my different articles! Contemplate subscribing to my new content material.
Acknowledgements
Clearly this challenge & article could be unimaginable if I didn’t stand on the shoulders of giants. It’s unimaginable to say all influences, however the next had been immediately associated:
[1] S. Es, J. James, L. Espinosa-Anke, S. Schockaert, RAGAS: Automated Analysis of Retrieval Augmented Era (2023),
arXiv:2309.15217
[2] C. Xu, Q. Solar, Ok. Zheng, X. Geng, P. Zhao, J. Feng, C. Tao, D. Jiang, WizardLM: Empowering Massive Language Fashions to Observe Complicated Directions (2023), arXiv:2304.12244
[3] Neighborhood, Massive Language Fashions, Wikipedia (2024), https://en.wikipedia.org/wiki/Large_language_model
[4] CNN & Each day Mail Dataset obtainable on Hugging Face, for more information see: https://huggingface.co/datasets/cnn_dailymail
Consider RAGs Rigorously or Perish was initially revealed in In direction of Information Science on Medium, the place individuals are persevering with the dialog by highlighting and responding to this story.