








































{kind=link}

Introduction
On the planet of AI, the place information drives choices, selecting the best instruments could make or break your venture. For Retrieval-Augmented Era methods extra generally referred to as RAG methods, PDFs are a goldmine of data—should you can unlock their contents. However PDFs are difficult; they’re usually filled with advanced layouts, embedded pictures, and hard-to-extract information.
In the event you’re not acquainted with RAG methods, such methods work by enhancing an AI mannequin’s potential to offer correct solutions by retrieving related info from exterior paperwork. Massive Language Fashions (LLMs), resembling GPT, use this information to ship extra knowledgeable, contextually conscious responses. This makes RAG methods particularly highly effective for dealing with advanced sources like PDFs, which regularly comprise tricky-to-access however beneficial content material.
The suitable PDF parser does not simply learn recordsdata—it turns them right into a wealth of actionable insights on your RAG functions. On this information, we’ll dive into the important options of high PDF parsers, serving to you discover the proper match to energy your subsequent RAG breakthrough.
Understanding PDF Parsing for RAG
What’s PDF Parsing?
PDF parsing is the method of extracting and changing the content material inside PDF recordsdata right into a structured format that may be simply processed and analyzed by software program functions. This contains textual content, pictures, and tables which are embedded throughout the doc.
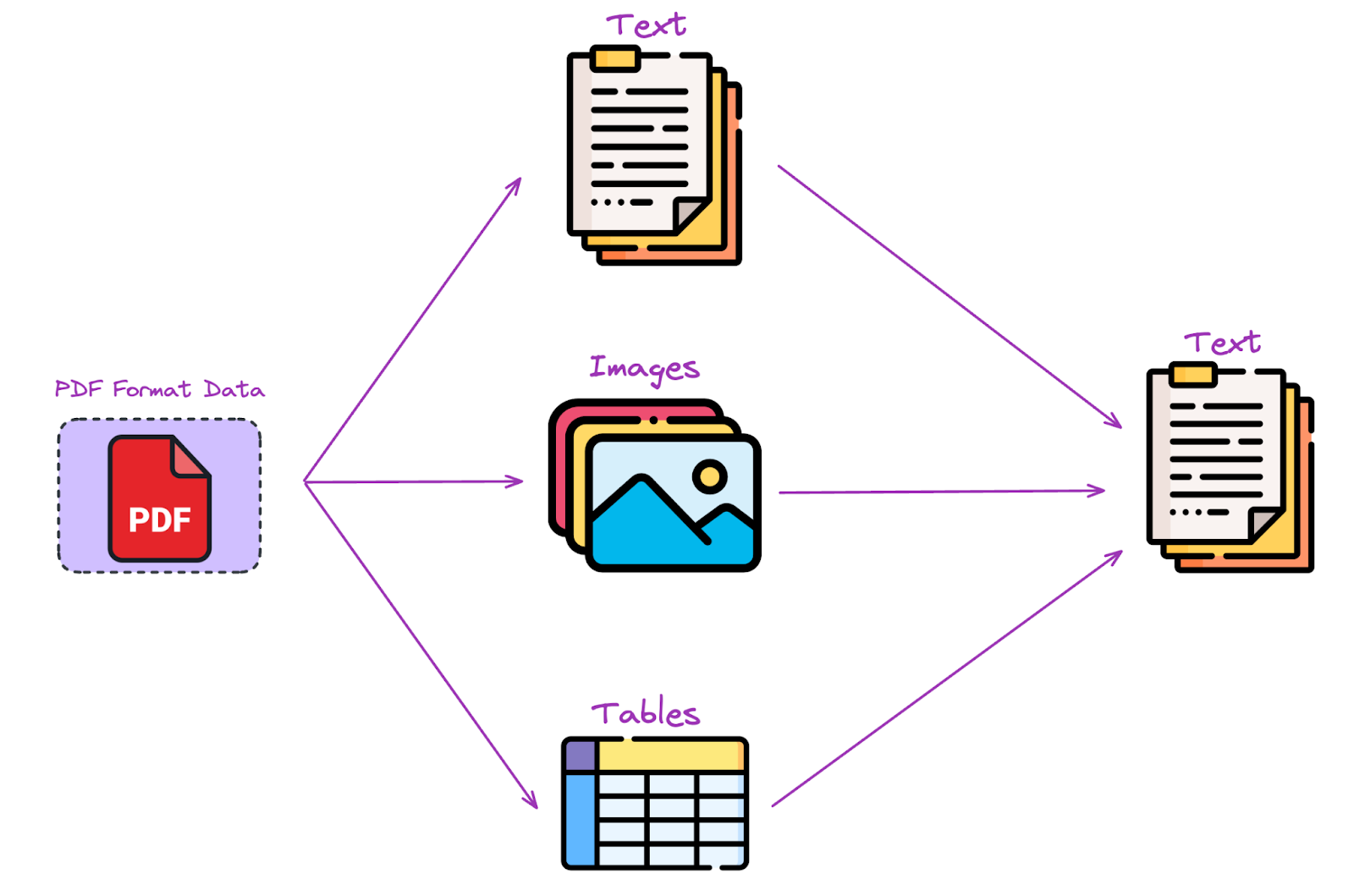
Why is PDF Parsing Essential for RAG Functions?
RAG methods depend on high-quality, structured information to generate correct and ctextually related outputs. PDFs, usually used for official paperwork, enterprise experiences, and authorized contracts, comprise a wealth of data however are infamous for his or her advanced layouts and unstructured information. Efficient PDF parsing ensures that this info is precisely extracted and structured, offering the RAG system with the dependable information it must perform optimally. With out sturdy PDF parsing, essential information may very well be misinterpreted or misplaced, resulting in inaccurate outcomes and undermining the effectiveness of the RAG utility.
The Function of PDF Parsing in Enhancing RAG Efficiency
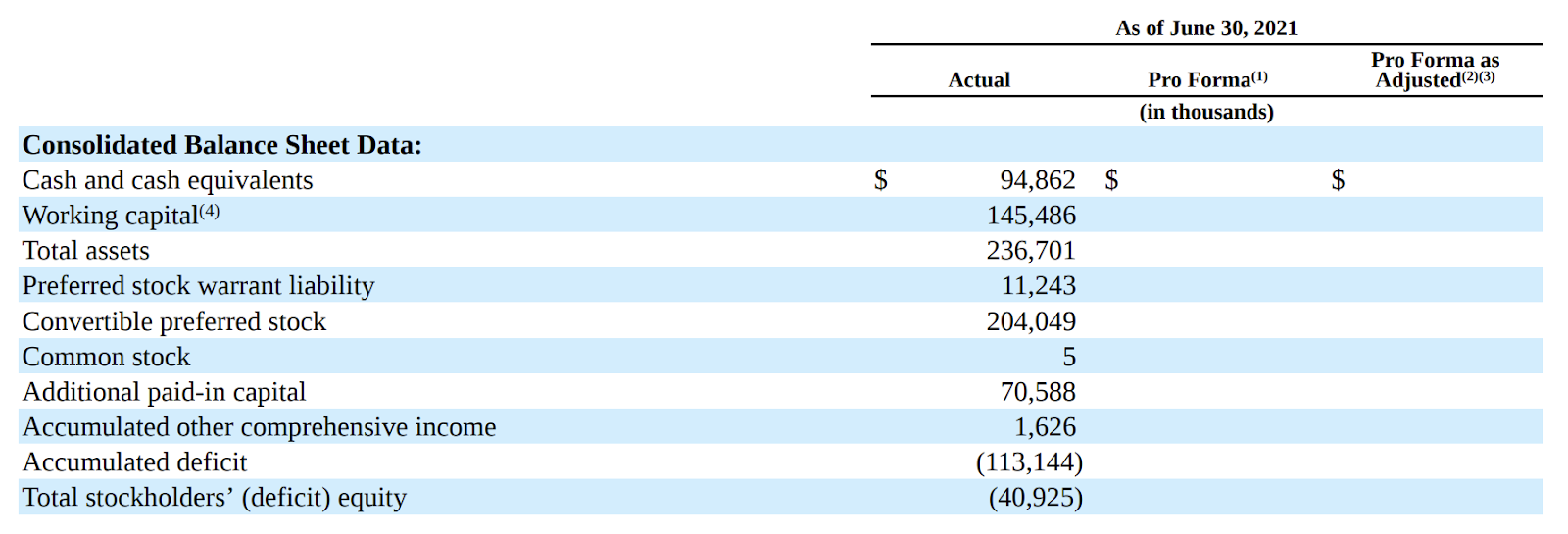
Tables are a primary instance of the complexities concerned in PDF parsing. Contemplate the S-1 doc used within the registration of securities. The S-1 comprises detailed monetary details about an organization’s enterprise operations, use of proceeds, and administration, usually offered in tabular type. Precisely extracting these tables is essential as a result of even a minor error can result in important inaccuracies in monetary reporting or compliance with SEC (Securities and Alternate Fee rules), which is a U.S. authorities company answerable for regulating the securities markets and defending traders. It ensures that firms present correct and clear info, significantly via paperwork just like the S-1, that are filed when an organization plans to go public or provide new securities.
A well-designed PDF parser can deal with these advanced tables, sustaining the construction and relationships between the info factors. This precision ensures that when the RAG system retrieves and makes use of this info, it does so precisely, resulting in extra dependable outputs.
For instance, we are able to current the next desk from our monetary S1 PDF to an LLM and request it to carry out a selected evaluation primarily based on the info offered.
By enhancing the extraction accuracy and preserving the integrity of advanced layouts, PDF parsing performs an important function in elevating the efficiency of RAG methods, significantly in use instances like monetary doc evaluation, the place precision is non-negotiable.
Key Concerns When Selecting a PDF Parser for RAG
When choosing a PDF parser to be used in a RAG system, it is important to judge a number of essential elements to make sure that the parser meets your particular wants. Under are the important thing issues to bear in mind:
Accuracy is essential to creating positive that the info extracted from PDFs is reliable and could be simply utilized in RAG functions. Poor extraction can result in misunderstandings and harm the efficiency of AI fashions.
Means to Keep Doc Construction
- Conserving the unique construction of the doc is essential to guarantee that the extracted information retains its unique that means. This contains preserving the format, order, and connections between completely different components (e.g., headers, footnotes, tables).
Assist for Varied PDF Varieties
- PDFs are available in numerous types, together with digitally created PDFs, scanned PDFs, interactive PDFs, and people with embedded media. A parser’s potential to deal with several types of PDFs ensures flexibility in working with a variety of paperwork.
Integration Capabilities with RAG Frameworks
- For a PDF parser to be helpful in an RAG system, it must work nicely with the present setup. This contains having the ability to ship extracted information immediately into the system for indexing, looking, and producing outcomes.
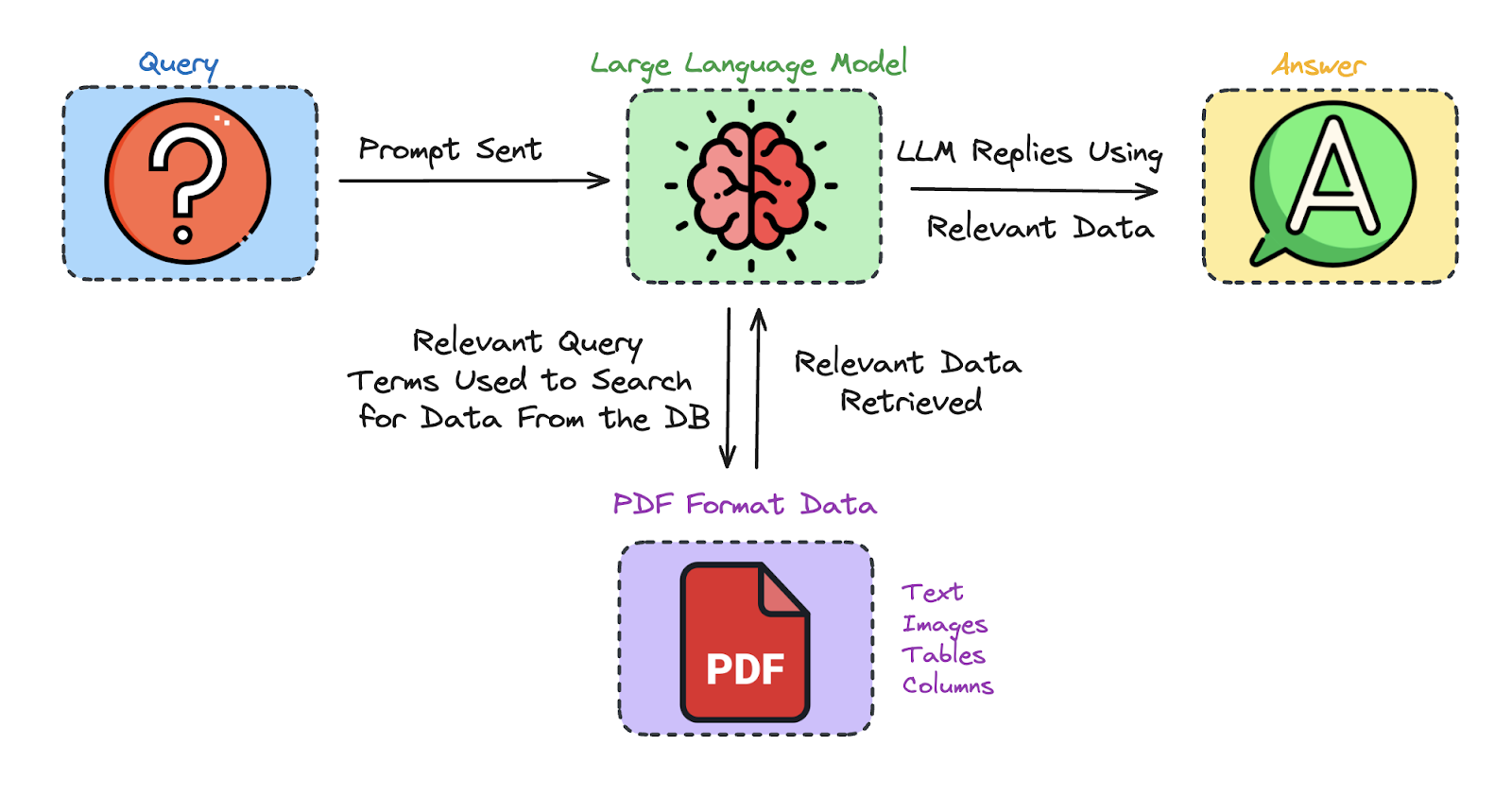
Challenges in PDF Parsing for RAG
RAG methods rely closely on correct and structured information to perform successfully. PDFs, nonetheless, usually current important challenges as a consequence of their advanced formatting, various content material sorts, and inconsistent buildings. Listed here are the first challenges in PDF parsing for RAG:
Coping with Complicated Layouts and Formatting
PDFs usually embrace multi-column layouts, blended textual content and pictures, footnotes, and headers, all of which make it tough to extract info in a linear, structured format. The non-linear nature of many PDFs can confuse parsers, resulting in jumbled or incomplete information extraction.

A monetary report may need tables, charts, and a number of columns of textual content on the identical web page. Take the above format for instance, extracting the related info whereas sustaining the context and order could be difficult for traditional parsers.
Wrongly Extracted Knowledge:

Dealing with Scanned Paperwork and Photographs
Many PDFs comprise scanned pictures of paperwork relatively than digital textual content. These paperwork often do require Optical Character Recognition (OCR) to transform the pictures into textual content, however OCR can wrestle with poor picture high quality, uncommon fonts, or handwritten notes, and in most PDF Parsers the info from picture extraction function is just not out there.

Extracting Tables and Structured Knowledge
Tables are a gold mine of knowledge, nonetheless, extracting tables from PDFs is notoriously tough as a result of various methods tables are formatted. Tables might span a number of pages, embrace merged cells, or have irregular buildings, making it arduous for parsers to accurately determine and extract the info.
An S-1 submitting would possibly embrace advanced tables with monetary information that have to be extracted precisely for evaluation. Normal parsers might misread rows and columns, resulting in incorrect information extraction.
Earlier than anticipating your RAG system to investigate numerical information saved in essential tables, it’s important to first consider how successfully this information is extracted and despatched to the LLM. Making certain correct extraction is essential to figuring out how dependable the mannequin’s calculations might be.

Comparative Evaluation of Well-liked PDF Parsers for RAG
On this part of the article, we might be evaluating a few of the most well-known PDF parsers on the difficult facets of PDF extraction utilizing the AllBirds S1 discussion board. Needless to say the AllBirds S1 PDF is 700 pages, and extremely advanced PDF parsers that poses important challenges, making this comparability part an actual take a look at of the 5 parsers talked about beneath. In additional frequent and fewer advanced PDF paperwork, these PDF Parsers would possibly provide higher efficiency when extracting the wanted information.
Multi-Column Layouts Comparability
Under is an instance of a multi-column format extracted from the AllBirds S1 type. Whereas this format is easy for human readers, who can simply monitor the info of every column, many PDF parsers wrestle with such layouts. Some parsers might incorrectly interpret the content material by studying it as a single vertical column, relatively than recognizing the logical circulate throughout a number of columns. This misinterpretation can result in errors in information extraction, making it difficult to precisely retrieve and analyze the knowledge contained inside such paperwork. Correct dealing with of multi-column codecs is important for guaranteeing correct information extraction in advanced PDFs.
PDF Parsers in Motion
Now let’s examine how some PDF parsers extract multi-column format information.
a) PyPDF1 (Multi-Column Layouts Comparability)
Nicole BrookshirePeter WernerCalise ChengKatherine DenbyCooley LLP3 Embarcadero Middle, twentieth FloorSan Francisco, CA 94111(415) 693-2000Daniel LiVP, LegalAllbirds, Inc.730 Montgomery StreetSan Francisco, CA 94111(628) 225-4848Stelios G. SaffosRichard A. KlineBenjamin J. CohenBrittany D. RuizLatham & Watkins LLP1271 Avenue of the AmericasNew York, New York 10020(212) 906-1200The first problem with the PyPDF1 parser is its lack of ability to neatly separate extracted information into distinct traces, resulting in a cluttered and complicated output. Moreover, whereas the parser acknowledges the idea of a number of columns, it fails to correctly insert areas between them. This misalignment of textual content may cause important challenges for RAG methods, making it tough for the mannequin to precisely interpret and course of the knowledge. This lack of clear separation and spacing finally hampers the effectiveness of the RAG system, because the extracted information doesn’t precisely replicate the construction of the unique doc.
b) PyPDF2 (Multi-Column Layouts Comparability)
Nicole Brookshire Daniel Li Stelios G. Saffos
Peter Werner VP, Authorized Richard A. Kline
Calise Cheng Allbirds, Inc. Benjamin J. Cohen
Katherine Denby 730 Montgomery Road Brittany D. Ruiz
Cooley LLP San Francisco, CA 94111 Latham & Watkins LLP
3 Embarcadero Middle, twentieth Flooring (628) 225-4848 1271 Avenue of the Americas
San Francisco, CA 94111 New York, New York 10020
(415) 693-2000 (212) 906-1200As proven above, though the PyPDF2 parser separates the extracted information into separate traces making it simpler to know, it nonetheless struggles with successfully dealing with multi-column layouts. As an alternative of recognizing the logical circulate of textual content throughout columns, it mistakenly extracts the info as if the columns had been single vertical traces. This misalignment ends in jumbled textual content that fails to protect the meant construction of the content material, making it tough to learn or analyze the extracted info precisely. Correct parsing instruments ought to have the ability to determine and accurately course of such advanced layouts to take care of the integrity of the unique doc’s construction.
c) PDFMiner (Multi-Column Layouts Comparability)
Nicole Brookshire
Peter Werner
Calise Cheng
Katherine Denby
Cooley LLP
3 Embarcadero Middle, twentieth Flooring
San Francisco, CA 94111
(415) 693-2000
Copies to:
Daniel Li
VP, Authorized
Allbirds, Inc.
730 Montgomery Road
San Francisco, CA 94111
(628) 225-4848
Stelios G. Saffos
Richard A. Kline
Benjamin J. Cohen
Brittany D. Ruiz
Latham & Watkins LLP
1271 Avenue of the Americas
New York, New York 10020
(212) 906-1200The PDFMiner parser handles the multi-column format with precision, precisely extracting the info as meant. It accurately identifies the circulate of textual content throughout columns, preserving the doc’s unique construction and guaranteeing that the extracted content material stays clear and logically organized. This functionality makes PDFMiner a dependable alternative for parsing advanced layouts, the place sustaining the integrity of the unique format is essential.
d) Tika-Python (Multi-Column Layouts Comparability)
Copies to:
Nicole Brookshire
Peter Werner
Calise Cheng
Katherine Denby
Cooley LLP
3 Embarcadero Middle, twentieth Flooring
San Francisco, CA 94111
(415) 693-2000
Daniel Li
VP, Authorized
Allbirds, Inc.
730 Montgomery Road
San Francisco, CA 94111
(628) 225-4848
Stelios G. Saffos
Richard A. Kline
Benjamin J. Cohen
Brittany D. Ruiz
Latham & Watkins LLP
1271 Avenue of the Americas
New York, New York 10020
(212) 906-1200Though the Tika-Python parser doesn’t match the precision of PDFMiner in extracting information from multi-column layouts, it nonetheless demonstrates a robust potential to know and interpret the construction of such information. Whereas the output will not be as polished, Tika-Python successfully acknowledges the multi-column format, guaranteeing that the general construction of the content material is preserved to an inexpensive extent. This makes it a dependable possibility when dealing with advanced layouts, even when some refinement is likely to be mandatory post-extraction
e) Llama Parser (Multi-Column Layouts Comparability)
Nicole Brookshire Daniel Lilc.Street1 Stelios G. Saffosen
Peter Werner VP, Legany A 9411 Richard A. Kline
Katherine DenCalise Chengby 730 Montgome C848Allbirds, Ir Benjamin J. CohizLLPcasBrittany D. Rus meri20
3 Embarcadero Middle 94111Cooley LLP, twentieth Flooring San Francisco,-4(628) 225 1271 Avenue of the Ak 100Latham & Watkin
San Francisco, CA0(415) 693-200 New York, New Yor0(212) 906-120The Llama Parser struggled with the multi-column format, extracting the info in a linear, vertical format relatively than recognizing the logical circulate throughout the columns. This ends in disjointed and hard-to-follow information extraction, diminishing its effectiveness for paperwork with advanced layouts.
Desk Comparability
Extracting information from tables, particularly after they comprise monetary info, is essential for guaranteeing that essential calculations and analyses could be carried out precisely. Monetary information, resembling steadiness sheets, revenue and loss statements, and different quantitative info, is usually structured in tables inside PDFs. The flexibility of a PDF parser to accurately extract this information is important for sustaining the integrity of monetary experiences and performing subsequent analyses. Under is a comparability of how completely different PDF parsers deal with the extraction of such information.
Under is an instance desk extracted from the identical Allbird S1 discussion board with the intention to take a look at our parsers on.

Now let’s examine how some PDF parsers extract tabular information.
a) PyPDF1 (Desk Comparability)
☐CALCULATION OF REGISTRATION FEETitle of Every Class ofSecurities To Be RegisteredProposed MaximumAggregate Providing PriceAmount ofRegistration FeeClass A standard inventory, $0.0001 par worth per share$100,000,000$10,910(1)Estimated solely for the aim of calculating the registration charge pursuant to Rule 457(o) below the Securities Act of 1933, as amended.(2)Much like its dealing with of multi-column format information, the PyPDF1 parser struggles with extracting information from tables. Simply because it tends to misread the construction of multi-column textual content by studying it as a single vertical line, it equally fails to take care of the correct formatting and alignment of desk information, usually resulting in disorganized and inaccurate outputs. This limitation makes PyPDF1 much less dependable for duties that require exact extraction of structured information, resembling monetary tables.
b) PyPDF2 (Desk Comparability)
Much like its dealing with of multi-column format information, the PyPDF2 parser struggles with extracting information from tables. Simply because it tends to misread the construction of multi-column textual content by studying it as a single vertical line, nonetheless in contrast to the PyPDF1 Parser the PyPDF2 Parser splits the info into separate traces.
CALCULATION OF REGISTRATION FEE
Title of Every Class of Proposed Most Quantity of
Securities To Be Registered Combination Providing Value(1)(2) Registration Payment
Class A standard inventory, $0.0001 par worth per share $100,000,000 $10,910c) PDFMiner (Desk Comparability)
Though the PDFMiner parser understands the fundamentals of extracting information from particular person cells, it nonetheless struggles with sustaining the right order of column information. This problem turns into obvious when sure cells are misplaced, such because the “Class A standard inventory, $0.0001 par worth per share” cell, which might find yourself within the improper sequence. This misalignment compromises the accuracy of the extracted information, making it much less dependable for exact evaluation or reporting.
CALCULATION OF REGISTRATION FEE
Class A standard inventory, $0.0001 par worth per share
Title of Every Class of
Securities To Be Registered
Proposed Most
Combination Providing Value
(1)(2)
$100,000,000
Quantity of
Registration Payment
$10,910d) Tika-Python (Desk Comparability)
As demonstrated beneath, the Tika-Python parser misinterprets the multi-column information into vertical extraction., making it not that a lot better in comparison with the PyPDF1 and a couple of Parsers.
CALCULATION OF REGISTRATION FEE
Title of Every Class of
Securities To Be Registered
Proposed Most
Combination Providing Value
Quantity of
Registration Payment
Class A standard inventory, $0.0001 par worth per share $100,000,000 $10,910e) Llama Parser (Desk Comparision)
CALCULATION OF REGISTRATION FEE
Securities To Be RegisteTitle of Every Class ofred Combination Providing PriceProposed Most(1)(2) Registration Quantity ofFee
Class A standard inventory, $0.0001 par worth per share $100,000,000 $10,910The Llama Parser confronted challenges when extracting information from tables, failing to seize the construction precisely. This resulted in misaligned or incomplete information, making it tough to interpret the desk’s contents successfully.
Picture Comparability
On this part, we’ll consider the efficiency of our PDF parsers in extracting information from pictures embedded throughout the doc.

Llama Parser
Textual content: Desk of Contents
allbids
Betler Issues In A Higher Manner applies
nof solely to our merchandise, however to
the whole lot we do. That'$ why we're
pioneering the primary Sustainable Public
Fairness ProvidingThe PyPDF1, PyPDF2, PDFMiner, and Tika-Python libraries are all restricted to extracting textual content and metadata from PDFs, however they don’t possess the potential to extract information from pictures. Alternatively, the Llama Parser demonstrated the flexibility to precisely extract information from pictures embedded throughout the PDF, offering dependable and exact outcomes for image-based content material.
Notice that the beneath abstract relies on how the PDF Parsers have dealt with the given challenges offered within the AllBirds S1 Kind.
Greatest Practices for PDF Parsing in RAG Functions
Efficient PDF parsing in RAG methods depends closely on pre-processing methods to boost the accuracy and construction of the extracted information. By making use of strategies tailor-made to the particular challenges of scanned paperwork, advanced layouts, or low-quality pictures, the parsing high quality could be considerably improved.
Pre-processing Strategies to Enhance Parsing High quality
Pre-processing PDFs earlier than parsing can considerably enhance the accuracy and high quality of the extracted information, particularly when coping with scanned paperwork, advanced layouts, or low-quality pictures.
Listed here are some dependable methods:
- Textual content Normalization: Standardize the textual content earlier than parsing by eradicating undesirable characters, correcting encoding points, and normalizing font sizes and types.
- Changing PDFs to HTML: Changing PDFs to HTML provides beneficial HTML parts, resembling
,
, and, which inherently protect the construction of the doc, like headers, paragraphs, and tables. This helps in organizing the content material extra successfully in comparison with PDFs. For instance, changing a PDF to HTML can lead to structured output like:
Desk of Contents
As filed with the Securities and Alternate Fee on August 31, 2021
Registration No. 333-
UNITED STATES
SECURITIES AND EXCHANGE COMMISSION
Washington, D.C. 20549
FORM S-1
REGISTRATION STATEMENT
UNDER
THE SECURITIES ACT OF 1933
Allbirds, Inc.- Web page Choice: Extract solely the related pages of a PDF to cut back processing time and concentrate on an important sections. This may be executed by manually or programmatically choosing pages that comprise the required info. In the event you’re extracting information from a 700-page PDF, choosing solely the pages with steadiness sheets can save important processing time.
- Picture Enhancement: Through the use of picture enhancement methods, we are able to enhance the readability of the textual content in scanned PDFs. This contains adjusting distinction, brightness, and backbone, all of which contribute to creating OCR simpler. These steps assist be certain that the extracted information is extra correct and dependable.
Testing Our PDF Parser Inside a RAG System
On this part, we’ll take our testing to the subsequent degree by integrating every of our PDF parsers into a completely practical RAG system, leveraging the Llama 3 mannequin because the system’s LLM.
We are going to consider the mannequin’s responses to particular questions and assess how the standard of the PDF parsers in extracting information impacts the accuracy of the RAG system’s replies. By doing so, we are able to gauge the parser’s efficiency in dealing with a fancy doc just like the S1 submitting, which is lengthy, extremely detailed, and tough to parse. Even a minor error in information extraction may considerably impair the RAG mannequin’s potential to generate correct responses.
This technique will enable us to push the parsers to their limits, testing their robustness and accuracy in dealing with intricate authorized and monetary documentation.
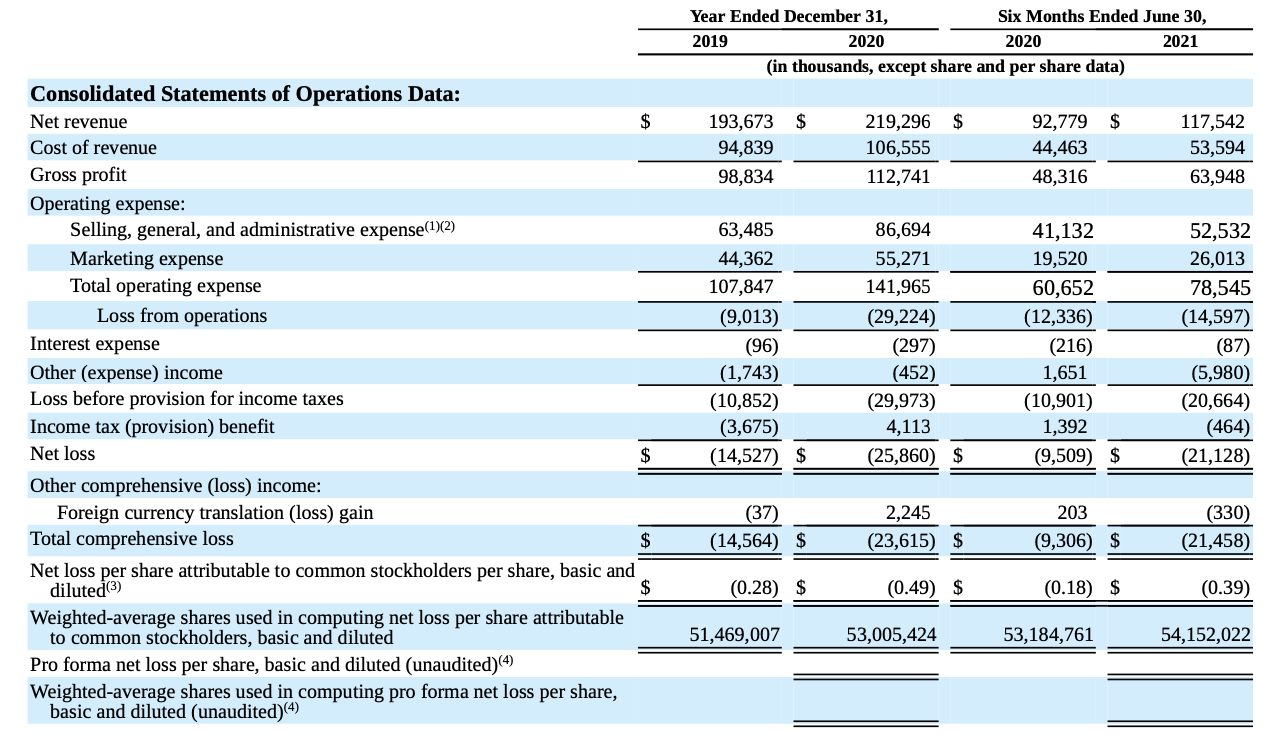
1) Query from Textual content: “What’s the whole internet income for Allbirds for the 12 months ended December 31, 2020?”
Right Reply: $219.3 million
PyPDF
- Reply: the conversion ratio is topic to adjustment upon the prevalence of sure occasions, as described beneath.
- Clarification: Incorrect reply. Because of the unstructured information extracted by PyPDF, the RAG system retrieves incorrect info.
PyPDF2
- Reply: in our Annual Report on Kind 10-Okay for the 12 months ended December 31, 2020. and $5.4 million and $7.4 million for the six months ended June 30, 2020 and 2021, respectively. (2) Consists of depreciation and amortization expense of ………..
- Clarification: Incorrect reply, regardless of the RAG system returning the right reply, “Allbirds, Inc. Web income $193,673 $219,296 $92,779 $117,542 December 31,” the mannequin was unable to offer an correct response as a result of poor parsing of the desk from the PDF. The messy extraction of knowledge hindered the system’s potential to interpret the numbers and ship a exact reply.
PDFMiner
- Reply: $219.3 million. In response to the given context, Allbirds’ internet income grew from $126.0 million in 2018 to $219.3 million in 2020, representing a compound annual development fee. Due to this fact, the overall internet income for Allbirds for the 12 months ended December 31, 2020 is $219.3 million.
- Clarification: Right reply.
Tika Python
- Reply: In response to the 10-Okay submitting of Allbirds, Inc. for the 12 months ended December 31, 2020, the overall internet income for the 12 months was $266.7 million. [1]
- Clarification: Incorrect reply, the retrieved information didn’t comprise the right response, thus the mannequin used it pre-stored information.
Llama Parser
- Reply: The overall internet income for Allbirds for the 12 months ended December 31, 2020 is $219,296. That is said within the given context.
- Clarification: Right reply.
Query from Desk: What’s the proposed most combination providing value for Allbirds, Inc.’s Class A standard inventory on this registration assertion?
Right reply: $100,000,000.
PyPDF
- Reply: the conversion ratio is topic to adjustment upon the prevalence of sure occasions, as described beneath.
- Clarification: Incorrect reply. Whereas the worth “$100,000,000” was current within the retrieved information, the massive quantity of retrieved info as a result of dangerous PDF Parsing overwhelmed the LLM, inflicting confusion and resulting in an inaccurate response.
PyPDF2
- Reply: The proposed most combination providing value for Allbirds, Inc.’s Class A standard inventory is $100,000,000.
- Clarification: Right reply., the right worth was returned within the retrieved information.
PDFMiner
- Reply: Reply: The proposed most combination providing value for Allbirds, Inc.’s Class A standard inventory on this registration assertion is just not specified within the context.
- Clarification: Incorrect reply, the right reply “$100,000,000” was not returned within the retrieved information, as a consequence of dangerous PDF parsing.
Tika Python
- Reply: The proposed most combination providing value for Allbirds, Inc.’s Class A standard inventory is just not specified within the given context.
- Clarification: Incorrect reply, the right reply “$100,000,000” was not returned within the retrieved information, as a consequence of dangerous PDF parsing.
Llama Parser
- Reply: The precise reply is just not offered within the given context.
- Clarification: Incorrect reply, the right reply “$100,000,000” was not returned within the retrieved information, as a consequence of dangerous PDF parsing.
Query from Picture: What number of company-operated shops did Allbirds have as of June 30, 2021?
Right reply: 100%
For this given query, we’ll solely be testing the Llama parser since it’s the solely mannequin able to studying information within the pictures.
- Reply: Not talked about within the offered context.
- Clarification: Incorrect reply, though the RAG system failed in retrieving the precise worth because the extracted information from the pdf picture which was: “35′, ‘ 27 international locations’, ‘ Firm-operatedstores as 2.5B”, the extracted information was fairly messy, inflicting the RAG system to not retrieve it.
We have requested 10 such questions pertaining to content material in textual content/desk and summarized the outcomes beneath.
Abstract of all outcomes
PyPDF: Struggles with each structured and unstructured information, resulting in frequent incorrect solutions. Knowledge extraction is messy, inflicting confusion in RAG mannequin responses.
PyPDF2: Performs higher with desk information however struggles with giant datasets that confuse the mannequin. It managed to return appropriate solutions for some structured textual content information.
PDFMiner: Typically appropriate with text-based questions however struggles with structured information like tables, usually lacking key info.
Tika Python: Extracts some information however depends on pre-stored information if appropriate information is not retrieved, resulting in frequent incorrect solutions for each textual content and desk questions.
Llama Parser: Greatest at dealing with structured textual content, however struggles with advanced picture information and messy desk extractions.
From all these experiments it is truthful to say that PDF parsers are but to catch up for advanced layouts and would possibly give a tricky time for downstream functions that require clear format consciousness and separation of blocks. Nonetheless we discovered PDFMiner and PyPDF2 pretty much as good beginning factors.
Enhancing Your RAG System with Superior PDF Parsing Options
As proven above, PDF parsers whereas extraordinarily versatile and straightforward to use, can generally wrestle with advanced doc layouts, resembling multi-column texts or embedded pictures, and will fail to precisely extract info. One efficient resolution to those challenges is utilizing Optical Character Recognition (OCR) to course of scanned paperwork or PDFs with intricate buildings. Nanonets, a number one supplier of AI-powered OCR options, affords superior instruments to boost PDF parsing for RAG methods.
Nanonets leverages a number of PDF parsers in addition to depends on AI and machine studying to effectively extract structured information from advanced PDFs, making it a strong device for enhancing RAG methods. It handles numerous doc sorts, together with scanned and multi-column PDFs, with excessive accuracy.

Nanonets assesses the professionals and cons of varied parsers and employs an clever system that adapts to every PDF uniquely Chat with PDF
Chat with any PDF utilizing our AI device: Unlock beneficial insights and get solutions to your questions in real-time.
Advantages for RAG Functions
- Accuracy: Nanonets offers exact information extraction, essential for dependable RAG outputs.
- Automation: It automates PDF parsing, lowering guide errors and rushing up information processing.
- Versatility: Helps a variety of PDF sorts, guaranteeing constant efficiency throughout completely different paperwork.
- Straightforward Integration: Nanonets integrates easily with current RAG frameworks through APIs.
Nanonets successfully handles advanced layouts, integrates OCR for scanned paperwork, and precisely extracts desk information, guaranteeing that the parsed info is each dependable and prepared for evaluation.
AI PDF Summarizer
Add PDFs or Photographs and Get Prompt Summaries or Dive Deeper with AI-powered Conversations.
Takeaways
In conclusion, choosing probably the most appropriate PDF parser on your RAG system is important to make sure correct and dependable information extraction. All through this information, we’ve got reviewed numerous PDF parsers, highlighting their strengths and weaknesses, significantly in dealing with advanced layouts resembling multi-column codecs and tables.
For efficient RAG functions, it is important to decide on a parser that not solely excels in textual content extraction accuracy but additionally preserves the unique doc’s construction. That is essential for sustaining the integrity of the extracted information, which immediately impacts the efficiency of the RAG system.
Finally, the only option of PDF parser will depend upon the particular wants of your RAG utility. Whether or not you prioritize accuracy, format preservation, or integration ease, choosing a parser that aligns along with your goals will considerably enhance the standard and reliability of your RAG outputs.
Please enter at the very least 3 characters