








































{kind=link}

What I discovered doing semantic search on U.S. Presidents with 4 language mannequin embeddings
I’m occupied with making an attempt to determine what’s inside a language mannequin embedding. You ought to be too, if one if these applies to you:
· The “thought processes” of huge language fashions (LLMs) intrigues you.
· You construct data-driven LLM methods, (particularly Retrieval Augmented Era methods) or would really like to.
· You propose to make use of LLMs sooner or later for analysis (formal or casual).
· The thought of a model new sort of language illustration intrigues you.
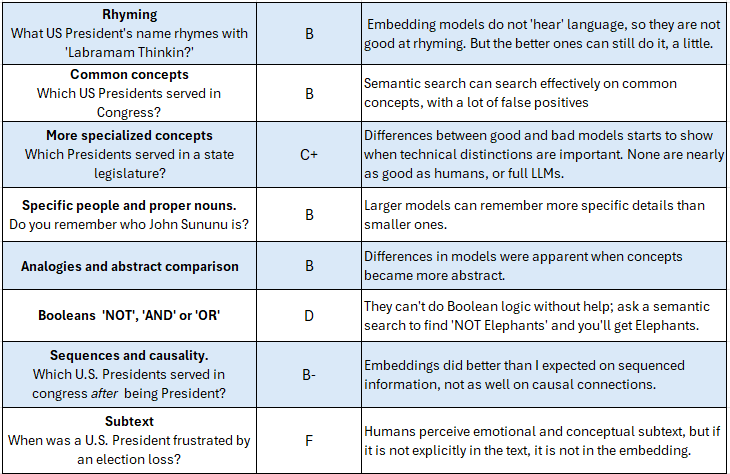
This weblog publish is meant to be comprehensible to any curious particular person, however even in case you are language mannequin specialist who works with them day by day I believe you’ll study some helpful issues, as I did. Right here’s a scorecard abstract of what I discovered about Language Mannequin embeddings by performing semantic searches with them:
The Scorecard
What do embeddings “see” nicely sufficient to seek out passages in a bigger dataset?
Together with many individuals, I’ve been fascinated by current progress making an attempt to look contained in the ‘Black Field’ of huge language fashions. There have not too long ago been some unimaginable breakthroughs in understanding the internal workings of language fashions. Listed here are examples of this work by Anthropic, Google, and a pleasant evaluate (Rai et al. 2024).
This exploration has related targets, however we’re learning embeddings, not full language fashions, and restricted to ‘black field’ inference from query responses, which might be nonetheless the one greatest interpretability methodology.
Embeddings are what are created by LLMs in step one, once they take a piece of textual content and switch it into a protracted string of numbers that the language mannequin networks can perceive and use. Embeddings are utilized in Retrieval Augmented Era (RAG) methods to permit looking on semantics (meanings) than are deeper than keyword-only searches. A set of texts, in my case the Wikipedia entries on U.S. Presidents, is damaged into small chunks of textual content and transformed to those numerical embeddings, then saved in a database. When a consumer asks a query, that query can also be transformed to embeddings. The RAG system then searches the database for an embedding much like the consumer question, utilizing a easy mathematical comparability between vectors, often a cosine similarity. That is the ‘retrieval’ step, and the instance code I present ends there. In a full RAG system, whichever most-similar textual content chunks are retrieved from the database are then given to an LLM to make use of them as ‘context’ for answering the unique query.
In the event you work with RAGs, there are numerous design variants of this fundamental course of. One of many design selections is selecting a selected embedding mannequin among the many many obtainable. Some fashions are longer, educated on extra information, and price more cash, however with out an understanding of what they’re like and the way they differ, the selection of which to make use of is usually guesswork. How a lot do they differ, actually?
In the event you don’t care concerning the RAG half
If you don’t care about RAG methods however are simply occupied with studying extra conceptually about how language fashions work, you may skip to the questions. Right here is the upshot: embeddings encapsulate fascinating information, info, data, and perhaps even knowledge gleaned from textual content, however neither their designers nor customers is aware of precisely what they seize and what they miss. This publish will seek for info with completely different embeddings to attempt to perceive what’s inside them, and what’s not.
The technical particulars: information, embeddings and chunk dimension
The dataset I’m utilizing incorporates Wikipedia entries about U.S. Presidents. I take advantage of LlamaIndex for creating and looking a vector database of those textual content entries. I used a smaller than normal chunk dimension, 128 tokens, as a result of bigger chunks are inclined to overlay extra content material and I wished a clear check of the system’s skill to seek out semantic matches. (I additionally examined chunk dimension 512 and outcomes on most exams have been related.)
I’ll exams 4 embeddings:
1. BGE (bge-small-en-v1.5) is sort of small at size 384. It the smallest of a line of BGE’s developed by the Beijing Academy of Synthetic Intelligence. For it’s dimension, it does nicely on benchmark exams of retrieval (see leaderboard). It’s F=free to make use of from HuggingFace.
2. ST (all-MiniLM-L6-v2) is one other 384-length embedding. It excels at sentence comparisons; I’ve used it earlier than for judging transcription accuracy. It was educated on the primary billion sentence-pair corpus, which was about half Reddit information. It is usually obtainable HuggingFace.

3. Ada (text-embedding-ada-002) is the embedding scheme that OpenAI used from GPT-2 via GPT-4. It’s for much longer than the opposite embeddings at size 1536, however it’s also older. How nicely can it compete with newer fashions?
4. Massive (text-embedding-3-large) is Ada’s alternative — newer, longer, educated on extra information, dearer. We’ll use it with the max size of three,072. Is it value the additional value and computing energy? Let’s discover out.
Questions, code obtainable on GitHub
There’s spreadsheet of query responses, a Jupyter pocket book, and textual content dataset of Presidential Wikipedia entries obtainable right here:
GitHub – nathanbos/blog_embeddings: Information to accompany Medium weblog on embeddings
Obtain the textual content and Jupyter pocket book if you wish to construct your individual; mine runs nicely on Google Colab.
The Spreadsheet of questions
I like to recommend downloading the spreadsheet to know these outcomes. It reveals the highest 20 textual content chunks returned for every query, plus a variety of variants and follow-ups. Observe the hyperlink and select ‘Obtain’ like this:

To browse the questions and responses, I discover it best to tug the textual content entry cell on the prime bigger, and tab via the responses to learn the textual content chunks there, as on this screenshot.
Not that that is the retrieved context solely, there isn’t any LLM synthesized response to those questions. The code has directions for get these, utilizing a question engine as a substitute of only a retriever as I did.
Offering understanding that goes past leaderboards
We’re going to do one thing countercultural on this publish: we’re going to deal with the precise outcomes of particular person query responses. This stands in distinction to present tendencies in LLM analysis, that are about utilizing bigger and bigger datasets and and presenting outcomes aggregated to a better and better stage. Corpus dimension issues lots for coaching, however that’s not as true for analysis, particularly if the purpose is human understanding.
For aggregated analysis of embedding search efficiency, seek the advice of the (very nicely carried out) HuggingFace leaderboard utilizing the (wonderful) MTEB dataset: https://huggingface.co/areas/mteb/leaderboard.
Leaderboards are nice for evaluating efficiency broadly, however usually are not nice for growing helpful understanding. Most leaderboards don’t publish precise question-by-question outcomes, limiting what could be understood about these outcomes. (They do often present code to re-run the exams your self.) Leaderboards additionally are inclined to deal with exams which are roughly inside the present expertise’s talents, which is cheap if the purpose is to match present fashions, however doesn’t assist perceive the bounds of the cutting-edge. To develop usable understanding about what methods can and can’t do, I discover there isn’t any substitute for back-and-forth testing and shut evaluation of outcomes.
What I’m presenting right here is principally a pilot examine. The subsequent step can be to do the work of growing bigger, exactly designed, understanding-focused check units, then conduct iterative exams targeted on deeper understanding of efficiency. This type of examine will seemingly solely occur at scale when funding businesses and educational disciplines past pc science begin caring about LLM interpretability. Within the meantime, you may study lots simply by asking.
Query: Which U.S. Presidents served within the Navy?
Let’s use the primary query in my check set as an example the ‘black field’ methodology of utilizing search to assist understanding.



The outcomes:
I gave the Navy query to every embedding index (database). Solely one of many 4 embeddings, Massive, was capable of finding all six Presidents who served within the Navy inside the prime ten hits. The desk under reveals the highest 10 discovered passages from for every embedding mannequin. See the spreadsheet for full textual content of the highest 20. There are duplicate Presidents on the listing, as a result of every Wikipedia entry has been divided into many particular person chunks, and any given search might discover multiple from the identical President.
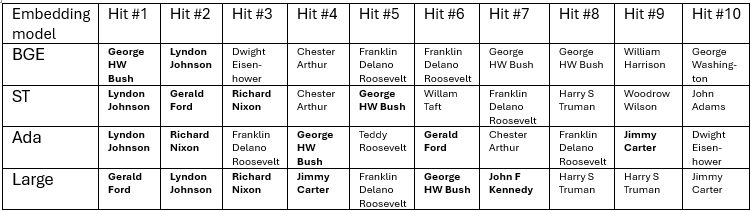
Why have been there so many incorrect hits? Let’s have a look at a few.
The primary false hit from BGE is a piece from Dwight D Eisenhower, a military normal in WW2, that has loads of navy content material however has nothing to do with the Navy. It seems that BGE does have some type of semantic illustration of ‘Navy’. BGE’s search was higher than what you’d get with a easy key phrase matches on ‘Navy’, as a result of it generalizes to different phrases that imply one thing related. But it surely generalized too indiscriminately, and did not differentiate Navy from normal navy subjects, e.g. it doesn’t persistently distinguish between the Navy and the Military. My mates in Annapolis wouldn’t be comfortable.
How did the 2 mid-level embedding fashions do? They appear to be clear on the Navy idea and may distinguish between the Navy and Military. However they every had many false hits on normal naval subjects; a piece on Chester A Arthur’s naval modernization efforts reveals up excessive on each lists. Different discovered sections have Presidential actions associated to the Navy, or ships named after Presidents, like the usS. Harry Truman.
The center two embedding fashions appear to have a technique to semantically signify ‘Navy’ however do not need a transparent semantic illustration of the idea ‘Served within the Navy’. This was sufficient to stop both ST or Ada from discovering all six Naval-serving Presidents within the prime ten.
On this query, Massive clearly outperforms the others, with six of the seven prime hits similar to the six serving Presidents: Gerald Ford, Richard Nixon, Lyndon B. Johnson, Jimmy Carter, John F. Kennedy, and George H. W. Bush. Massive seems to know not simply ‘Navy’ however ‘served within the Navy’.
What did Massive get fallacious?
What was the one mistake in Massive? It was the chunk on Franklin Delano Roosevelt’s work as Assistant Secretary of the Navy. On this capability, he was working for the Navy, however as a civilian worker, not within the Navy. I do know from private expertise that the excellence between lively obligation and civilian workers could be complicated. The primary time I did contract work for the navy I used to be unclear on which of my colleagues have been lively obligation versus civilian workers. A colleagues advised me, in his very respectful navy manner, that this distinction was necessary, and I wanted to get it straight, which I’ve since. (One other professional tip: don’t get the ranks confused.)
Query: Which U.S. Presidents labored as a civilian workers of the Navy?
On this query I probed to see whether or not the embeddings “understood” this distinction that I had at first missed: do they know the way civilian workers of the Navy differs from individuals really within the service? Each Roosevelts labored for the Navy in a civilian capability. Theodore had additionally been within the Military (main the cost of San Juan Hill), wrote books concerning the Navy, and constructed up the Navy as President, so there are numerous Navy-related chunks about TR, however he was by no means within the Navy. (Besides as Commander in Chief; this function technically makes all Presidents a part of the U.S. Navy, however that relationship didn’t have an effect on search hits.)
The outcomes of the civilian worker question could be seen within the outcomes spreadsheet. The primary hit for Massive and second for Ada is a passage describing a few of FDR’s work within the Navy, however this was partly luck as a result of it included the phrase ‘civilian’ in a unique context. Mentions have been manufactured from employees work by LBJ and Nixon, though it’s clear from the passages that they have been lively obligation on the time. (Some employees jobs could be stuffed by both navy or civilian appointees.) Point out of Teddy Roosevelt’s civilian employees work didn’t present up in any respect, which might stop an LLM from appropriately answering the query primarily based on these hits.
Total there have been solely minor distinction between the searches for Navy, “Within the Navy” and “civilian worker”. Asking immediately about active-duty Navy gave related outcomes. The bigger embedding fashions had some right associations, however general couldn’t make the required distinction nicely sufficient to reply the query.

Widespread Ideas
Query: Which U.S. Presidents have been U.S. Senators earlier than they have been President?
The entire vectors appear to usually perceive widespread ideas like this, and can provide good outcomes that an LLM might flip into an correct response. The embeddings might additionally differentiate between the U.S. Senate and U.S. Home of Representatives. They have been clear on the distinction between Vice President and President, the distinction between a lawyer and a choose, and the overall idea of an elected consultant.
Additionally they all did nicely when requested about Presidents who have been artists, musicians, or poker gamers. They struggled somewhat with ‘creator’ as a result of there have been so many false positives within the information relate to different authors.
Extra Specialised Ideas
As we noticed, they every have their representational limits, which for Massive was the idea of ‘civilian worker of the Navy.’ Additionally they all did poorly on the excellence between nationwide and state representatives.
Query: Which U.S. President served as elected representatives on the state stage?
Not one of the fashions returned all, and even a lot of the Presidents who served in state legislatures. The entire fashions principally returned hits relate to the U.S. Home of Representatives, with some references to states or governors. Massive’s first hit was on the right track: “Polk was elected to its state legislature in 1823”, however missed the remaining. This matter might use some extra probing, however usually this idea was a fail.
Query: Which US Presidents weren’t born in a US State?
All 4 embeddings returned Barack Obama as one of many prime hits to this query. This isn’t factual — Hawaii was a state in 1961 when Obama was born there, however the misinformation is prevalent sufficient (thanks, Donald) to indicate up within the encoding. The Presidents who have been born outdoors of the US have been the early ones, e.g. George Washington, as a result of Virginia was not a state when he was born. This implied truth was not accessible by way of the embeddings. William Henry Harrison was returned in all instances, as a result of his entry contains the passage “…he grew to become the final United States president not born as an American citizen”, however not one of the earlier President entries stated this immediately, so it was not discovered within the searches.
Seek for particular, semi-famous individuals and locations
Query: Which U.S. Presidents have been requested to ship a troublesome message to John Sununu?

People who find themselves sufficiently old to have adopted U.S. politics within the Nineteen Nineties will bear in mind this distinctive identify: John Sununu was governor of New Hampshire, was a considerably outstanding political determine, and served as George H.W. Bush’s (Bush #1's) chief of employees. However he isn’t talked about in Bush #1’s entry. He’s talked about in a unusual offhand anecdote within the entry for George W. Bush (Bush #2) the place Bush #1 requested Bush #2 to ask Sununu to resign. This was talked about, I believe, as an example one among Bush #2’s key strengths, likability, and the connection between the 2 Bushes. A seek for John Sununu, which might have been simple for a key phrase search because of the distinctive identify, fails to seek out this passage in three of the 4 embeddings. The one winner? Surprisingly, it’s BGE, the underdog.
There was one other fascinating sample: Massive returned a variety of hits on Bush #1, the President traditionally most related to Sununu, regardless that he’s by no means talked about within the returned passages. This appears greater than a coincidence; the embedding encoded some type of affiliation between Sununu and Bush #1 past what’s said within the textual content.
Which U.S. Presidents have been criticized by Helen Prejean?

I noticed the identical factor with a second semi-famous identify: Sister Helen Prejean was a reasonably well-known critic of the demise penalty; she wrote Useless Man Strolling and Wikipedia briefly notes that she criticized Bush #2’s insurance policies. Not one of the embeddings have been capable of finding the Helen Prejean point out which, once more, a key phrase search would have discovered simply. A number of of Massive’s prime hits are passages associated to the demise penalty, which looks like greater than a coincidence. As with Sununu, Massive seems to have some affiliation with the identify, regardless that it’s not represented clearly sufficient within the embedding vocabulary to do an efficient seek for it.
I examined a variety of different particular names, locations, and one bizarre phrase, ‘normalcy’, for the embedding fashions’ skill to encode and match them within the Wikipedia texts. The desk under reveals the hits and misses.
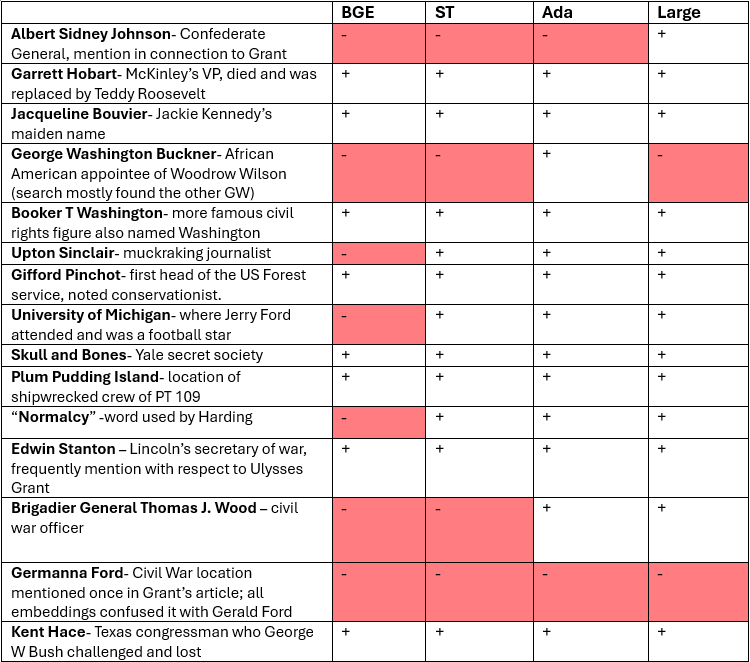
What does this inform us?
Language fashions encode extra frequently-encountered names, i.e. extra well-known individuals, however are much less prone to encode them the extra rare they’re. Bigger embeddings, usually, encode extra particular particulars. However there have been instances right here smaller fashions outperformed bigger ones, and fashions additionally typically needed to have some associations even with identify that they can not acknowledge nicely sufficient to seek out. An ideal comply with up on this is able to be a extra systematic examine of how noun frequency impacts illustration in embeddings.
Tangent #1: Rhyming
This was a little bit of a tangent however I had enjoyable testing it. Massive Language fashions can’t rhyme very nicely, as a result of they neither communicate or hear. Most people study to learn aloud first, and study to learn silently solely later. Once we learn silently, we will nonetheless subvocalize the phrases and ‘hear’ the rhymes in written verse as nicely. Language fashions don’t do that. Theirs is a silent, text-only world. They find out about rhyming solely from studying about it, and by no means get excellent at it. Embeddings might theoretically signify phonetics, and may often give correct phonetics for a given phrase. However I’ve been testing rhyming on and off since GPT-3, and LLMs often can’t search on this. Nonetheless, the embeddings shocked me a couple of occasions on this train.
Which President’s identify rhymes with ‘Gimme Barter?’

This one turned out to be simple; all 4 vectors gave “Jimmy Carter” as the primary returned hit. The cosine similarities have been lowish, however since this was basically a a number of selection check of Presidents, all of them made the match simply. I believe the spellings of Gimme Barter and Jimmy Carter are too related, so let’s attempt some more durable ones, with extra rigorously disguised rhymes that sound alike however have dissimilar spellings.
Which US President’s identify rhymes with Laybramam Thinkin’?

This one was more durable. Abraham Lincoln didn’t present up on BGE or ST’s prime ten hits, however was #1 for Ada and #3 for Massive.
Which US President’s names rhymes with Will-Ard Syl-Bor?
Millard Fillmore was a tricky rhyme. It was #2 for Ada, #5 for Massive, not within the prime 10 for the others. The shortage of Web poetry about President Fillmore looks like a spot somebody must fill. There have been loads of false hits for Invoice Clinton, maybe due to the double L’s?

And but, this exists: https://www.classroompoems.com/millard-fillmore-poem.htm. As a result of it’s the Web.
Which US President’s identify rhymes with Mayrolled Gored?
Gerald Ford was #7 for BGE , #4 for Ada, #5 for Massive.
Rhyming was not lined on the Gerald R. Ford Presidential Museum in my hometown of Grand Rapids, Michigan. I’d know, I visited it many occasions. Extra on that later.
Takeaway: the bigger embedding schemes can rhyme, somewhat, though perhaps much less nicely than a human. How are they doing this, and what are the bounds? Are they analyzing phonetics, making the most of current rhyming content material, or making good guesses one other manner? I do not know. Phonetic encoding in embedding methods looks like a high-quality thesis matter for some enterprising linguistics pupil, or perhaps a really nerdy English Lit main.
Embedding can’t do Booleans: no NOT, AND, or OR
Easy semantic search can’t do some fundamental operations the key phrase question methods usually can, and usually are not good at trying to find sequences of occasions.
Query: Which Presidents have been NOT Vice President first?
Doing a vector search with ‘NOT’ is much like the previous adage about telling somebody not to consider a Pink Elephant — saying the phrase often causes the particular person to take action. Embeddings haven’t any illustration of ‘Not Vice President’, they solely have Vice President.

The vector representing the query will comprise each “President” and “Vice President” and have a tendency to seek out chunks with each. One might attempt to kludge a compound question, looking first for all President, then all Vice Presidents, and subtract, however the restrict on contexts returned would stop returning the entire first listing, and isn’t assured to get the entire second. Boolean search with embeddings stays a downside.
Query: Which U.S. President was NOT elected as vice President and NEVER elected as President?
An exception the the ‘NOT’ fail: the entire embeddings might discover the passage saying that Gerald Ford was the one President that was by no means elected to be Vice President (appointed when Spiro Agnew resigned) or President (took Nixon’s place when he resigned, misplaced the re-election race to Jimmy Carter.) They have been capable of finding this as a result of the ‘not’ was explicitly represented within the textual content, with no inference wanted, and it’s also a widely known truth about Ford.
Why is there a double damaging on this query?
The pointless double damaging within the prior query made this search higher. A search on “Which U.S. President was not elected as both Vice President or President?” gave poorer outcomes. I added the double damaging wording as a hunch that the double negatives would have a compound impact of creating the question extra each damaging and make it simpler to attach the ‘not’ to each places of work. This doesn’t make grammatical sense however does make sense on the earth of superimposed semantics.
Gerald R. Ford’s many accomplishments
Individuals who have visited the Gerald R. Ford Presidential museum in my hometown of Grand Rapids, Michigan, a ample variety of occasions will likely be conscious that Ford made many necessary contributions regardless of not being elected to the best places of work. Simply placing that out there.

Query: Which Presidents have been President AND Vice President?
Semantic search has a form of weak AND, extra like an OR, however neither is a logical Boolean question. Embeddings don’t hyperlink ideas with strict logic. As a substitute, consider them as superimposing ideas on prime of one another on the identical vector. This question would discover chunks that load strongly on President (which is most of them on this dataset) and Vice President, however doesn’t implement the logical AND in any manner. On this dataset it provides some right hits, and loads of extraneous mentions of Vice Presidents. This seek for superimposed ideas is just not a real logical OR both.
Embeddings and sequences of actions
Do embeddings join ideas sequentially nicely sufficient to look on these sequences? My going-in assumption was that they can not, however the embeddings did higher than anticipated.
People have a selected varieties of reminiscence for sequence, referred to as episodic reminiscence. Tales are an necessary sort of data for us; we encode issues like private historical past, social info and likewise helpful classes as tales. We will additionally acknowledge tales much like ones that we already know. We will learn a narrative a couple of hero who fails due to his deadly flaw, or an abnormal one who rises to nice heights, and acknowledge not simply the ideas however the sequence of actions. In my earlier weblog publish on RAG search utilizing Aesop’s Fables, the RAG system didn’t appear to have any skill to look on sequences of actions. I anticipated an analogous failure right here, however the outcomes have been somewhat completely different.
Query: Which US Presidents served in Congress after being President?
There have been many Presidents who served in congress earlier than being President, however solely two who served in congress after being President. The entire Embeddings returned a passage from John Quincy Adams, which immediately provides the reply, as a prime hit: Adams and Andrew Johnson are the one former presidents to serve in Congress. All of them additionally individually discovered entries for Andrew Johnson within the prime 10. There have been a variety of false hits, however the important info was there.
The embeddings didn’t do as nicely on the follow-ups, like Which US Presidents served as judges after being President? However all did discover point out of Taft, who notably was the one particular person to function chief justice and president.
Does this actually signify efficiently looking on a sequence? Presumably not; in these instances the sequence could also be encapsulated in a single searchable idea, like “former President”. I nonetheless suspect that embeddings would badly underperform people on harder story-based searches. However it is a delicate level that will require extra evaluation.
What about causal connections?
Causal reasoning is such an necessary a part of human reasoning that I wished to individually check whether or not causal linkages are clearly represented and searchable. I examined these with two paired queries that had the causality reversed, and appeared each at which search hits have been returned, and the way the pairs completely different. Each query pairs have been fairly fascinating and outcomes are proven within the spreadsheet; I’ll deal with this one:
Query: When did a President’s motion trigger an necessary world occasion? -vs- When did an necessary world occasion trigger a President’s motion?
ST failed this check, it returned precisely the identical hits in the identical order for each queries. The causal connection was not represented clearly sufficient to have an effect on the search.
The entire embeddings returned a number of chunks associated to Presidential world journey, weirdly failing to separate touring from official actions.
Not one of the embeddings did nicely on the causal reversal. Each one had hits the place world occasions coincided with Presidential actions, typically very minor actions, with no causal hyperlink in both course. There all had false hits the place the logical linkage went within the fallacious instructions (Presidents inflicting occasions vs responding to occasions). There have been a number of instance of commentators calling out Presidential inaction, which means that ‘act’ and ‘not act’ are conflated. Causal language, particularly the phrase ‘trigger’ triggered loads of matches, even when it was not hooked up to a Presidential motion or world occasion.
A deeper exploration of how embeddings signify causality, perhaps in a important area like drugs, can be so as. What I noticed is an absence of proof that embeddings signify and appropriately use causality.
Analogies
Query: Which U.S. Presidents have been much like Simon Bolivar, and how?
Simon Bolivar, revolutionary chief and later political chief in South America, is typically referred to as the “George Washington of South America”. May the embedding fashions understand this analogy within the different course?
- BGE- Gave a really bizarre set of returned context, with no apparent connection moreover some mentions of Central/ South American.
- ST- Discovered a passage about William Henry Harrison’s 1828 journey to Colombia and feuding with Bolivar, and different mentions of Latin America, however made no summary matches.
- Ada- Discovered the Harrison passage + South America references, however no summary matches that I can inform.
- Massive- Returned George Washington as hit #5 behind Bolivar/ S America hits.
Massive received this check in a landslide. This hit reveals the clearest sample of bigger/higher vectors outperforming others at summary comparisons.


Summary ideas
I examined a variety of searches on extra summary ideas. Listed here are two examples:
Questions: Which US Presidents exceeded their energy?
BGE: prime hit: “In surveys of U.S. students rating presidents carried out since 1948, the highest three presidents are usually Lincoln, Washington, and Franklin Delano Roosevelt, though the order varies.” BGE discovered hits all associated to Presidential noteworthiness, particularly rankings by historians, I believe keying on the phrases ‘energy’ and ‘exceed’. This was a miss.
ST: “Roosevelt is broadly thought-about to be some of the necessary figures within the historical past of the US.” Identical patterns as BGE; a miss.
Ada: Ada’s hits have been all on the subject of Presidential energy, not simply status, and so have been extra on-target than the smaller fashions. There’s a widespread theme of accelerating energy, and a few passages that suggest exceeding, like this one: the Patriot Act “elevated authority of the chief department on the expense of judicial opinion…” Total, not a transparent win, however nearer.
Massive: It didn’t discover the very best 10 passages, however the hits have been extra on the right track. All had the idea of accelerating Presidential energy, and most has a taste of exceeding some earlier restrict, e.g. “conservative columnist George Will wrote in The Washington Put up that Theodore Roosevelt and Wilson have been the “progenitors of in the present day’s imperial presidency”
Once more, there was a sample of bigger fashions having extra exact, on-target abstractions. Massive was the one one to get near an accurate illustration of a President “exceeding their energy” however even this efficiency left loads of room for enchancment.
Embeddings don’t perceive subtext
Subtext is which means in a textual content that’s not immediately said. Individuals add which means to what they learn, making emotional associations, or recognizing associated ideas that transcend what’s immediately said, however embeddings do that solely in a really restricted manner.
Query: Give an instance of a time when a U.S. President expressed frustration with dropping an election?
In 1960, then-Vice President Richard Nixon misplaced a traditionally shut election to John F Kennedy. Deeply harm by the loss, Nixon determined to settle to return dwelling to his dwelling state of California and ran for governor in 1962. Nixon misplaced that race too. He famously introduced at a press convention, “You don’t (received’t) have Nixon to kick round anymore as a result of, gents, that is my final press convention,” thus ending his political profession, or so everybody thought.

What occurs whenever you seek for: “Give an instance of a time when a U.S. President expressed frustration with dropping an election”? Not one of the embeddings return this Nixon quote. Why? As a result of Wikipedia by no means immediately states that he was annoyed, or had another particular emotion; that’s all subtext. When a mature human reads “You received’t have Nixon to kick round anymore”, we acknowledge some implied feelings, in all probability with out consciously making an attempt to take action. This is perhaps so automated when studying that one thinks it’s within the textual content. However in his passage the emotion isn’t immediately said. And whether it is subtext, not textual content, an embedding will (in all probability) not have the ability to signify it or have the ability to search it.
Wikipedia avoids speculating on emotional subtext as part of fact-based reporting. Utilizing subtext as a substitute of textual content can also be thought-about good tradecraft for fiction writers, even when the purpose is to convey sturdy feelings. A standard piece of recommendation for brand spanking new writers is, “present, don’t inform.” Expert writers reveal what characters are pondering and feeling with out immediately stating it. There’s even a reputation for pedantic writing that explains issues too immediately, it’s referred to as “on-the-nose dialogue”.
However “present, don’t inform” makes some content material invisible to embeddings, and thus to vector-based RAG retrieval methods. This presents some basic limitations to what could be present in RAG system within the area of emotional subtext, but additionally different layers of which means that transcend what’s immediately said. I additionally did loads of probing round ideas like Presidential errors, Presidential intentions, and analytic patterns which are simply past what’s immediately said within the textual content. Embedding-based search usually failed on this, principally returning solely direct statements, even once they weren’t related.
Why are embeddings shallow in comparison with Massive Language Fashions?
Massive Language Fashions like Claude and GPT-4 have the power to know subtext; they do a reputable job explaining tales, jokes, poetry and Taylor Swift track lyrics. So why can’t embeddings do this?
Language fashions are comprised of layers, and usually the decrease layers are shallower types of processing, representing elements like grammar and floor meanings, whereas larger stage of abstraction happen in larger layers. Embeddings are the primary stage in language mannequin processing; they convert textual content into numbers after which let the LLM take over. That is the very best clarification I do know of for why the embedding search exams appear to plateau at shallower ranges of semantic matching.
Embedding weren’t initially designed for RAGs; utilizing them for semantic search is a intelligent, however finally restricted secondary utilization. That’s altering, as embedding methods are being optimized for search. BGE was to some prolong optimized for search, and ST was designed for sentence comparability; I’d say that is why each BGE and ST weren’t too far behind Ada and Massive regardless of being a fraction of the dimensions. Massive was in all probability designed with search in thoughts to a restricted extent. But it surely was simple to push every of them to their semantic limits, as in contrast with the type of semantics processed by full massive language fashions.
Conclusion
What did we study, conceptually, about embeddings in his train?
The embedding fashions, general, shocked me on a couple of issues. The semantic depth was lower than I anticipated, primarily based on the efficiency of the language fashions that use them. However they outperformed my expectations on a couple of issues I anticipated them to fail utterly at, like rhyming and trying to find sequenced actions. This exercise piqued my curiosity in probing some extra particular areas; maybe it did for you as nicely.
For RAG builders, this illuminated a few of the particular ways in which bigger fashions might outperform smaller ones, together with the precisions of their illustration, the breadth of information and the vary of abstractions. As a someday RAG builder, I’ve been skeptical that paying extra for embeddings would result in higher efficiency, however this train satisfied me that embedding selection could make a distinction for some purposes.
Embeddings methods will proceed to incrementally enhance, however I believe some basic breakthroughs will likely be wanted on this space. There’s some present analysis on improvements like common textual content embeddings.
Data graphs are a preferred present technique to complement semantic search. Graphs are good for making cross-document connections, however the LLM-derived graphs I’ve seen are semantically fairly shallow. To get semantic depth from a data graph in all probability requires a professionally-developed ontology to be obtainable to function a place to begin; these can be found for some specialised fields.
My very own most popular methodology is to enhance textual content with extra textual content. Since full language fashions can understand and perceive which means that’s not in embeddings, why not have a language mannequin pre-process and annotate the textual content in your corpus with the particular varieties of semantics you have an interest in? This is perhaps too costly for actually enormous datasets, however for information within the small to medium vary it may be a superb answer.
I experimented with including annotations to the Presidential dataset. To make emotional subtext searchable I had GPT4o write narratives for every President highlighting the non-public and emotional content material. These annotations have been added again into the corpus. They don’t seem to be nice prose, however the idea labored. GPT’s annotation of the Nixon entry included the sentence: “The defeat was a bitter capsule to swallow, compounded by his loss within the 1962 California gubernatorial race. In a second of frustration, Nixon declared to the press, ‘You received’t have Nixon to kick round anymore,’ signaling what many believed to be the tip of his political profession”. This successfully turned subtext into textual content, making is searchable.
I experimented with a variety of varieties of annotations. One which I used to be significantly comfortable used Claude to look at every Presidency and make feedback on underlying system dynamical phenomena like delayed suggestions and optimistic suggestions loops. Looking on these phrases on the unique textual content gave nothing helpful, however vastly improved with annotations. Claude’s analyses weren’t good, and even at all times right, but it surely discovered and annotated sufficient respectable examples that searches utilizing system dynamic language discovered helpful content material.


Embeddings Are Sort of Shallow was initially revealed in In direction of Information Science on Medium, the place individuals are persevering with the dialog by highlighting and responding to this story.