































")





 and Ether ((ETH) Following Fed Assembly On account of Poor Liquidity, Greater Beta")
 is Bullish As lengthy Because it Stays Above This Crucial Resistance Stage: Analyst")







")
{kind=link}

Generate constant assignments on the fly throughout completely different implementation environments
A core a part of operating an experiment is to assign an experimental unit (for example a buyer) to a particular therapy (fee button variant, advertising and marketing push notification framing). Usually this task wants to fulfill the next circumstances:
- It must be random.
- It must be secure. If the shopper comes again to the display screen, they must be uncovered to the identical widget variant.
- It must be retrieved or generated very shortly.
- It must be accessible after the precise task so it may be analyzed.
When organizations first begin their experimentation journey, a typical sample is to pre-generate assignments, retailer it in a database after which retrieve it on the time of task. It is a completely legitimate methodology to make use of and works nice while you’re beginning off. Nonetheless, as you begin to scale in buyer and experiment volumes, this methodology turns into more durable and more durable to keep up and use reliably. You’ve bought to handle the complexity of storage, make sure that assignments are literally random and retrieve the task reliably.
Utilizing ‘hash areas’ helps remedy a few of these issues at scale. It’s a very easy answer however isn’t as broadly often known as it most likely ought to. This weblog is an try at explaining the approach. There are hyperlinks to code in several languages on the finish. Nonetheless in the event you’d like you may also instantly soar to code right here.
Organising
We’re operating an experiment to check which variant of a progress bar on our buyer app drives probably the most engagement. There are three variants: Management (the default expertise), Variant A and Variant B.
We now have 10 million clients that use our app each week and we need to make sure that these 10 million clients get randomly assigned to one of many three variants. Every time the shopper comes again to the app they need to see the identical variant. We would like management to be assigned with a 50% chance, Variant 1 to be assigned with a 30% chance and Variant 2 to be assigned with a 20% chance.
probability_assignments = {"Management": 50, "Variant 1": 30, "Variant 2": 20}
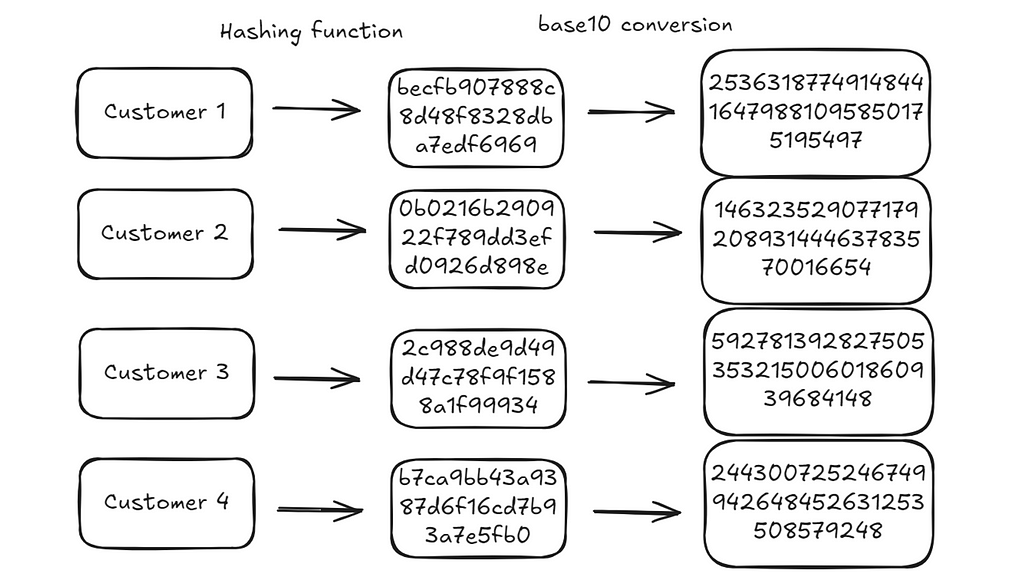
To make issues less complicated, we’ll begin with 4 clients. These clients have IDs that we use to confer with them. These IDs are usually both GUIDs (one thing like "b7be65e3-c616-4a56-b90a-e546728a6640") or integers (like 1019222, 1028333). Any of those ID sorts would work however to make issues simpler to comply with we’ll merely assume that these IDs are: “Customer1”, “Customer2”, “Customer3”, “Customer4”.

Hashing buyer IDs
This methodology primarily depends on utilizing hash algorithms that include some very fascinating properties. Hashing algorithms take a string of arbitrary size and map it to a ‘hash’ of a set size. The simplest method to perceive that is by some examples.
A hash operate, takes a string and maps it to a continuing hash house. Within the instance beneath, a hash operate (on this case md5) takes the phrases: “Hiya”, “World”, “Hiya World” and “Hiya WorLd” (notice the capital L) and maps it to an alphanumeric string of 32 characters.

Just a few necessary issues to notice:
- The hashes are all the similar size.
- A minor distinction within the enter (capital L as a substitute of small L) modifications the hash.
- Hashes are a hexadecimal string. That’s, they comprise of the numbers 0 to 9 and the primary six alphabets (a, b, c, d, e and f).
We are able to use this similar logic and get hashes for our 4 clients:
import hashlib
representative_customers = ["Customer1", "Customer2", "Customer3", "Customer4"]
def get_hash(customer_id):
hash_object = hashlib.md5(customer_id.encode())
return hash_object.hexdigest()
{buyer: get_hash(buyer) for buyer in representative_customers}
# {'Customer1': 'becfb907888c8d48f8328dba7edf6969',
# 'Customer2': '0b0216b290922f789dd3efd0926d898e',
# 'Customer3': '2c988de9d49d47c78f9f1588a1f99934',
# 'Customer4': 'b7ca9bb43a9387d6f16cd7b93a7e5fb0'}

Hexadecimal strings are simply representations of numbers in base 16. We are able to convert them to integers in base 10.
⚠️ One necessary notice right here: We not often want to make use of the total hash. In follow (for example within the linked code) we use a a lot smaller a part of the hash (first 10 characters). Right here we use the total hash to make explanations a bit simpler.
def get_integer_representation_of_hash(customer_id):
hash_value = get_hash(customer_id)
return int(hash_value, 16)
{
buyer: get_integer_representation_of_hash(buyer)
for buyer in representative_customers
}
# {'Customer1': 253631877491484416479881095850175195497,
# 'Customer2': 14632352907717920893144463783570016654,
# 'Customer3': 59278139282750535321500601860939684148,
# 'Customer4': 244300725246749942648452631253508579248}
There are two necessary properties of those integers:
- These integers are secure: Given a set enter (“Customer1”), the hashing algorithm will at all times give the identical output.
- These integers are uniformly distributed: This one hasn’t been defined but and principally applies to cryptographic hash features (similar to md5). Uniformity is a design requirement for these hash features. In the event that they weren’t uniformly distributed, the probabilities of collisions (getting the identical output for various inputs) could be larger and weaken the safety of the hash. There are some explorations of the uniformity property.
Now that we have now an integer illustration of every ID that’s secure (at all times has the identical worth) and uniformly distributed, we will use it to get to an task.
From integer representations to task
Going again to our chance assignments, we need to assign clients to variants with the next distribution:
{"Management": 50, "Variant 1": 30, "Variant 2": 20}
If we had 100 slots, we will divide them into 3 buckets the place the variety of slots represents the chance we need to assign to that bucket. As an example, in our instance, we divide the integer vary 0–99 (100 models), into 0–49 (50 models), 50–79 (30 models) and 80–99 (20 models).

def divide_space_into_partitions(prob_distribution):
partition_ranges = []
begin = 0
for partition in prob_distribution:
partition_ranges.append((begin, begin + partition))
begin += partition
return partition_ranges
divide_space_into_partitions(prob_distribution=probability_assignments.values())
# notice that that is zero listed, decrease certain inclusive and higher certain unique
# [(0, 50), (50, 80), (80, 100)]
Now, if we assign a buyer to one of many 100 slots randomly, the resultant distribution ought to then be equal to our meant distribution. One other means to consider that is, if we select a quantity randomly between 0 and 99, there’s a 50% probability it’ll be between 0 and 49, 30% probability it’ll be between 50 and 79 and 20% probability it’ll be between 80 and 99.
The one remaining step is to map the shopper integers we generated to one in all these hundred slots. We do that by extracting the final two digits of the integer generated and utilizing that because the task. As an example, the final two digits for buyer 1 are 97 (you possibly can test the diagram beneath). This falls within the third bucket (Variant 2) and therefore the shopper is assigned to Variant 2.
We repeat this course of iteratively for every buyer. After we’re accomplished with all our clients, we must always discover that the tip distribution will likely be what we’d count on: 50% of consumers are in management, 30% in variant 1, 20% in variant 2.
def assign_groups(customer_id, partitions):
hash_value = get_relevant_place_value(customer_id, 100)
for idx, (begin, finish) in enumerate(partitions):
if begin <= hash_value < finish:
return idx
return None
partitions = divide_space_into_partitions(
prob_distribution=probability_assignments.values()
)
teams = {
buyer: listing(probability_assignments.keys())[assign_groups(customer, partitions)]
for buyer in representative_customers
}
# output
# {'Customer1': 'Variant 2',
# 'Customer2': 'Variant 1',
# 'Customer3': 'Management',
# 'Customer4': 'Management'}
The linked gist has a replication of the above for 1,000,000 clients the place we will observe that clients are distributed within the anticipated proportions.
# ensuing proportions from a simulation on 1 million clients.
{'Variant 1': 0.299799, 'Variant 2': 0.199512, 'Management': 0.500689
Sensible concerns
Including ‘salt’ to an experiment
In follow, while you’re operating a number of experiments throughout completely different components of your product, it’s widespread follow so as to add in a “salt” to the IDs earlier than you hash them. This salt may be something: the experiment title, an experiment id, the title of the characteristic and so forth. This ensures that the shopper to bucket mapping is at all times completely different throughout experiments provided that the salt is completely different. That is actually useful to make sure that buyer aren’t at all times falling in the identical buckets. As an example, you don’t need particular clients to at all times fall into the management therapy if it simply occurs that the management is allotted the primary 50 buckets in all of your experiments. That is easy to implement.
salt_id = "f7d1b7e4-3f1d-4b7b-8f3d-3f1d4b7b8f3d"
customer_with_salt_id = [
f"{customer}{salt_id}" for customer in representative_customers
]
# ['Customer1f7d1b7e4-3f1d-4b7b-8f3d-3f1d4b7b8f3d',
# 'Customer2f7d1b7e4-3f1d-4b7b-8f3d-3f1d4b7b8f3d',
# 'Customer3f7d1b7e4-3f1d-4b7b-8f3d-3f1d4b7b8f3d',
# 'Customer4f7d1b7e4-3f1d-4b7b-8f3d-3f1d4b7b8f3d']
Growing the partitioned house
On this instance, we used an area that consisted of 100 attainable slots (or partitions). In case you needed to assign chances that have been a number of decimal locations, you’d simply take the final n digits of the integer generated.
So for example in the event you needed to assign chances that have been as much as two decimal locations, you can take the final 4 digits of the integer generated. That’s, the worth of place_value beneath could be 10000.
def get_relevant_place_value(customer_id, place_value):
hash_value = get_integer_representation_of_hash(customer_id)
return hash_value % place_value
Cross atmosphere availability
Lastly, one motive this methodology is so highly effective and enticing in follow is that you would be able to replicate the method identically throughout completely different implementation environments. The core hashing algorithm will at all times provide the similar hash in any atmosphere so long as the enter is identical. All you want is the CustomerId, SaltIdand the meant chance distribution. You could find completely different implementations right here:
Wrapping up
If you wish to generate random, quick and secure assignments throughout completely different implementation environments, you should use the next:
- Use a cryptographic hashing operate (similar to md5) to generate a hash from a novel ID + some ‘salt’.
- Convert this into an integer in base 10.
- Extract the final two digits. You possibly can extract extra in case you have extra superb grained necessities.
- Use these digits to assign the ID to one in all a set of pre-defined experimental buckets.

In case you’ve learn this far, thanks for following alongside and hope you’ve discovered this convenient. All photographs within the article are mine. Be happy to make use of them!
Huge due to Deniss Zenkovs for introducing me to the concept and suggesting fascinating extensions.
Steady and quick randomization utilizing hash areas was initially revealed in In direction of Knowledge Science on Medium, the place persons are persevering with the dialog by highlighting and responding to this story.