







 in New Analysis")



")
Home windows,Intel")



















{kind=link}

That is in all probability the answer to your subsequent NLP drawback.
On this story we introduce and broadly discover the subject of weak supervision in machine studying. Weak supervision is one studying paradigm in machine studying that began gaining notable consideration lately. To wrap it up in a nutshell, full supervision requires that we have now a coaching set (x,y) the place y is the proper label for x; in the meantime, weak supervision assumes a normal setting (x, y’) the place y’ doesn’t need to be right (i.e., it’s doubtlessly incorrect; a weak label). Furthermore, in weak supervision we will have a number of weak supervisors so one can have (x, y’1,y’2,…,y’F) for every instance the place every y’j comes from a unique supply and is doubtlessly incorrect.
Desk of Contents
∘ Downside Assertion
∘ Basic Framework
∘ Basic Structure
∘ Snorkel
∘ Weak Supervision Instance
Downside Assertion
In additional sensible phrases, weak supervision goes in the direction of fixing what I wish to name the supervised machine studying dilemma. If you’re a enterprise or an individual with a brand new thought in machine studying you will want knowledge. It’s typically not that onerous to gather many samples (x1, x2, …, xm) and typically, it may be even completed programtically; nevertheless, the true dilemma is that you’ll want to rent human annotators to label this knowledge and pay some $Z per label. The problem is not only that you could be not know if the mission is price that a lot, it’s additionally that you could be not afford hiring annotators to start with as this course of could be fairly costy particularly in fields comparable to legislation and drugs.
You could be pondering however how does weak supervision resolve any of this? In easy phrases, as a substitute of paying annotators to present you labels, you ask them to present you some generic guidelines that may be typically inaccurate in labeling the info (which takes far much less money and time). In some instances, it might be even trivial in your growth group to determine these guidelines themselves (e.g., if the duty doesn’t require knowledgeable annotators).
Now let’s consider an instance usecase. You are attempting to construct an NLP system that may masks phrases equivalent to delicate data comparable to telephone numbers, names and addresses. As an alternative of hiring folks to label phrases in a corpus of sentences that you’ve got collected, you write some capabilities that routinely label all the info based mostly on whether or not the phrase is all numbers (seemingly however not definitely a telephone quantity), whether or not the phrase begins with a capital letter whereas not at first of the sentence (seemingly however not definitely a reputation) and and many others. then coaching you system on the weakly labeled knowledge. It could cross your thoughts that the educated mannequin gained’t be any higher than such labeling sources however that’s incorrect; weak supervision fashions are by design meant to generalize past the labeling sources by understanding that there’s uncertainty and infrequently accounting for it in a approach or one other.
Basic Framework
Now let’s formally take a look at the framework of weak supervision as its employed in pure language processing.
✦ Given
A set of F labeling capabilities {L1 L2,…,LF} the place Lj assigns a weak (i.e., doubtlessly incorrect) label given an enter x the place any labeling perform Lj could also be any of:
- Crowdsource annotator (typically they aren’t that correct)
- Label because of distance supervision (i.e., extracted from one other data base)
- Weak mannequin (e.g., inherently weak or educated on one other process)
- Heuristic perform (e.g., label remark based mostly on the existence of a key phrase or sample or outlined by area knowledgeable)
- Gazetteers (e.g., label remark based mostly on its incidence in a particular checklist)
- LLM Invocation underneath a particular immediate P (current work)
- Any perform usually that (ideally) performs higher than random guess in guessing the label of x.
It’s typically assumed that Li might abstain from giving a label (e.g., a heuristic perform comparable to “if the phrase has numbers then label telephone quantity else don’t label”).
Suppose the coaching set has N examples, then this given is equal to an (N,F) weak label matrix within the case of sequence classification. For token classification with a sequence of size of T, it’s a (N,T,F) matrix of weak labels.
✦ Needed
To coach a mannequin M that successfully leverages the weakly labeled knowledge together with any robust knowledge if it exists.
✦ Widespread NLP Duties
- Sequence classification (e.g., sentiment evaluation) or token classification (e.g., named entity recognition) the place labeling capabilities are often heuristic capabilities or gazetteers.
- Low useful resource translation (x→y) the place labeling perform(s) is often a weaker translation mannequin (e.g., a translation mannequin within the reverse path (y→x) so as to add extra (x,y) translation pairs.
Basic Structure
For sequence or token classification duties, the most typical structure within the literature plausibly takes this kind:
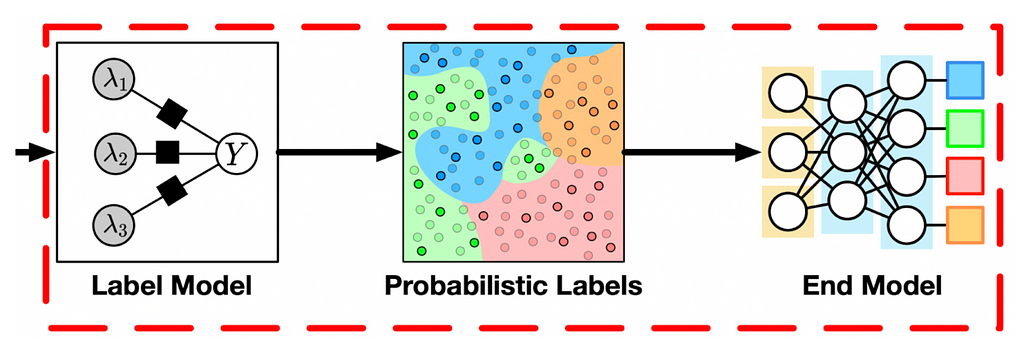
The label mannequin learns to map the outputs from the label capabilities to probabilistic or deterministic labels that are used to coach the tip mannequin. In different phrases, it takes the (N,F) or (N,T,F) label matrix mentioned above and returns (N) or (N,T) matrix of labels (which are sometimes probabilistic (i.e., comfortable) labels).
The finish mannequin is used individually after this step and is simply an strange classifier that operates on comfortable labels (cross-entropy loss permits that) produced by the label mannequin. Some architectures use deep studying to merge label and finish fashions.
Discover that when we have now educated the label mannequin, we use it to generate the labels for the tip mannequin and after that we not use the label mannequin. On this sense, that is fairly totally different from staking even when the label capabilities are different machine studying fashions.
One other structure, which is the default within the case of translation (and fewer widespread for sequence/token classification), is to weight the weak examples (src, trg) pair based mostly on their high quality (often just one labeling perform for translation which is a weak mannequin within the reverse path as mentioned earlier). Such weight can then be used within the loss perform so the mannequin learns extra from higher high quality examples and fewer from decrease high quality ones. Approaches on this case try to plot strategies to guage the standard of a particular instance. One strategy for instance makes use of the roundtrip BLEU rating (i.e., interprets sentence to focus on then again to supply) to estimate such weight.
Snorkel
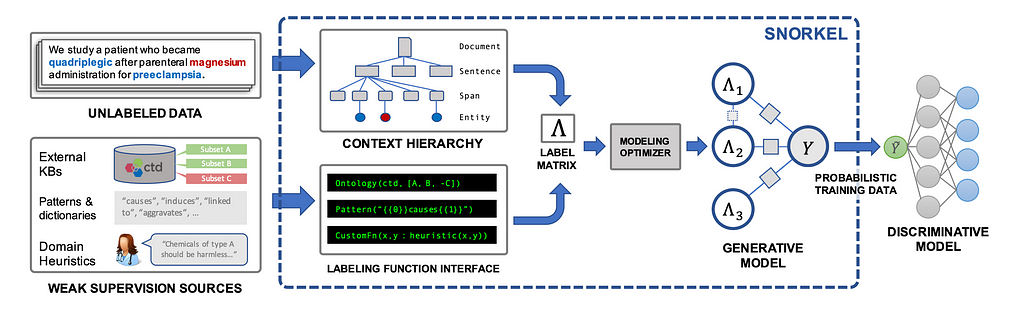
To see an instance of how the label mannequin can work, we will take a look at Snorkel which is arguably probably the most elementary work in weaks supervision for sequence classification.
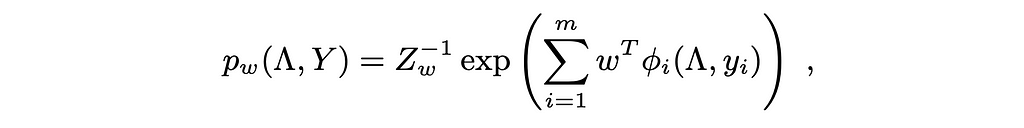
In Snorkel, the authors had been considering discovering P(yi|Λ(xi)) the place Λ(xi) is the weak label vector of the ith instance. Clearly, as soon as this likelihood is discovered, we will use it as comfortable label for the tip mannequin (as a result of as we stated cross entropy loss can deal with comfortable labels). Additionally clearly, if we have now P(y, Λ(x)) then we will simply use to search out P(y|Λ(x)).
We see from the equation above that they used the identical speculation as logistic regression to mannequin P(y, Λ(x)) (Z is for normalization as in Sigmoid/Softmax). The distinction is that as a substitute of w.x we have now w.φ(Λ(xi),yi). Particularly, φ(Λ(xi),yi) is a vector of dimensionality 2F+|C|. F is the variety of labeling capabilities as talked about earlier; in the meantime, C is the set of labeling perform pairs which might be correlated (thus, |C| is the variety of correlated pairs). Authors consult with a technique in one other paper to automate developing C which we gained’t delve into right here for brevity.
The vector φ(Λ(xi),yi) comprises:
- F binary components to specify whether or not every of the labeling capabilities has abstained for given instance
- F binary components to specify whether or not every of the labeling capabilities is the same as the true label y (right here y shall be left as a variable; it’s an enter to the distribution) given this instance
- C binary components to specify whether or not every correlated pair made the identical vote given this instance
They then practice this label fashions (i.e., estimate the weights vector of size 2F+|C|) by fixing the next goal (minimizing unfavourable log marginal probability):
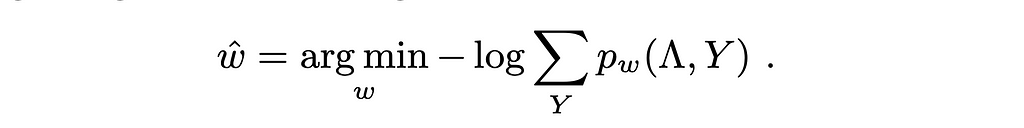
Discover that they don’t want details about y as this goal is solved no matter any particular worth of it as indicated by the sum. When you look carefully (undo the unfavourable and the log) chances are you’ll discover that that is equal to discovering the weights that maximize the likelihood for any of the true labels.
As soon as the label mannequin is educated, they use it to provide N comfortable labels P(y1|Λ(x1)), P(y2|Λ(x2)),…,P(yN|Λ(xN)) and use that to usually practice some discriminative mannequin (i.e., a classifier).
Weak Supervision Instance
Snorkel has a superb tutorial for spam classification right here. Skweak is one other bundle (and paper) that’s elementary for weak supervision for token classification. That is an instance on find out how to get began with Skweak as proven on their Github:
First outline labeling capabilities:
import spacy, re
from skweak import heuristics, gazetteers, generative, utils
### LF 1: heuristic to detect occurrences of MONEY entities
def money_detector(doc):
for tok in doc[1:]:
if tok.textual content[0].isdigit() and tok.nbor(-1).is_currency:
yield tok.i-1, tok.i+1, "MONEY"
lf1 = heuristics.FunctionAnnotator("cash", money_detector)
### LF 2: detection of years with a regex
lf2= heuristics.TokenConstraintAnnotator("years", lambda tok: re.match("(19|20)d{2}$",
tok.textual content), "DATE")
### LF 3: a gazetteer with a number of names
NAMES = [("Barack", "Obama"), ("Donald", "Trump"), ("Joe", "Biden")]
trie = gazetteers.Trie(NAMES)
lf3 = gazetteers.GazetteerAnnotator("presidents", {"PERSON":trie})
Apply them on the corpus
# We create a corpus (right here with a single textual content)
nlp = spacy.load("en_core_web_sm")
doc = nlp("Donald Trump paid $750 in federal revenue taxes in 2016")
# apply the labelling capabilities
doc = lf3(lf2(lf1(doc)))
Create and match the label mannequin
# create and match the HMM aggregation mannequin
hmm = generative.HMM("hmm", ["PERSON", "DATE", "MONEY"])
hmm.match([doc]*10)
# as soon as fitted, we merely apply the mannequin to mixture all capabilities
doc = hmm(doc)
# we will then visualise the ultimate end result (in Jupyter)
utils.display_entities(doc, "hmm")
Then you possibly can after all practice a classifier on high of this on utilizing the estimated comfortable labels.
On this article, we explored the issue addressed by weak supervision, offered a proper definition, and outlined the final structure sometimes employed on this context. We additionally delved into Snorkel, one of many foundational fashions in weak supervision, and concluded with a sensible instance as an example how weak supervision could be utilized.

Hope you discovered the article to be helpful. Till subsequent time, au revoir.
References
[1] Zhang, J. et al. (2021) Wrench: A complete benchmark for weak supervision, arXiv.org. Obtainable at: https://arxiv.org/abs/2109.11377 .
[2] Ratner, A. et al. (2017) Snorkel: Fast Coaching Knowledge Creation with weak supervision, arXiv.org. Obtainable at: https://arxiv.org/abs/1711.10160.
[3] NorskRegnesentral (2021) NorskRegnesentral/skweak: Skweak: A software program toolkit for weak supervision utilized to NLP duties, GitHub. Obtainable at: https://github.com/NorskRegnesentral/skweak.
An Intuitive Overview of Weak Supervision was initially revealed in In direction of Knowledge Science on Medium, the place individuals are persevering with the dialog by highlighting and responding to this story.