







 in New Analysis")



")
Home windows,Intel")



















{kind=link}

The basics of planning and decision-making
A classical modular autonomous driving system usually consists of notion, prediction, planning, and management. Till round 2023, AI (synthetic intelligence) or ML (machine studying) primarily enhanced notion in most mass-production autonomous driving programs, with its affect diminishing in downstream elements. In stark distinction to the low integration of AI within the planning stack, end-to-end notion programs (such because the BEV, or birds-eye-view notion pipeline) have been deployed in mass manufacturing autos.
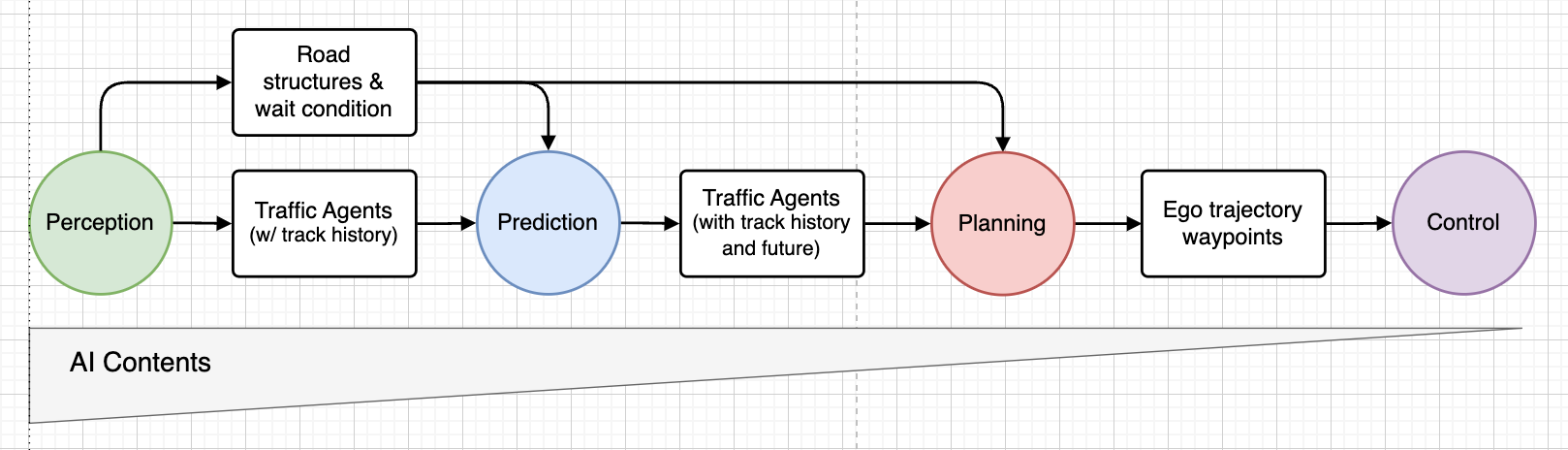
There are a number of causes for this. A classical stack primarily based on a human-crafted framework is extra explainable and will be iterated quicker to repair subject take a look at points (inside hours) in comparison with machine learning-driven options (which may take days or perhaps weeks). Nonetheless, it doesn’t make sense to let available human driving information sit idle. Furthermore, rising computing energy is extra scalable than increasing the engineering crew.
Happily, there was a robust pattern in each academia and business to vary this case. First, downstream modules have gotten more and more data-driven and can also be built-in by way of completely different interfaces, such because the one proposed in CVPR 2023’s greatest paper, UniAD. Furthermore, pushed by the ever-growing wave of Generative AI, a single unified vision-language-action (VLA) mannequin reveals nice potential for dealing with complicated robotics duties (RT-2 in academia, TeslaBot and 1X in business) and autonomous driving (GAIA-1, DriveVLM in academia, and Wayve AI driver, Tesla FSD in business). This brings the toolsets of AI and data-driven improvement from the notion stack to the planning stack.
This weblog put up goals to introduce the issue settings, current methodologies, and challenges of the planning stack, within the type of a crash course for notion engineers. As a notion engineer, I lastly had a while over the previous couple of weeks to systematically be taught the classical planning stack, and I want to share what I discovered. I will even share my ideas on how AI will help from the attitude of an AI practitioner.
The supposed viewers for this put up is AI practitioners who work within the subject of autonomous driving, specifically, notion engineers.
The article is a bit lengthy (11100 phrases), and the desk of contents beneath will almost definitely assist those that wish to do fast ctrl+F searches with the key phrases.
Desk of Contents (ToC)
Why be taught planning?
What's planning?
The issue formulation
The Glossary of Planning
Habits Planning
Frenet vs Cartesian programs
Classical tools-the troika of planning
Looking
Sampling
Optimization
Business practices of planning
Path-speed decoupled planning
Joint spatiotemporal planning
Choice making
What and why?
MDP and POMDP
Worth iteration and Coverage iteration
AlphaGo and MCTS-when nets meet bushes
MPDM (and successors) in autonomous driving
Business practices of resolution making
Bushes
No bushes
Self-Reflections
Why NN in planning?
What about e2e NN planners?
Can we do with out prediction?
Can we do with simply nets however no bushes?
Can we use LLMs to make choices?
The pattern of evolution
Why be taught planning?
This brings us to an attention-grabbing query: why be taught planning, particularly the classical stack, within the period of AI?
From a problem-solving perspective, understanding your prospects’ challenges higher will allow you, as a notion engineer, to serve your downstream prospects extra successfully, even when your most important focus stays on notion work.
Machine studying is a instrument, not an answer. Probably the most environment friendly option to resolve issues is to mix new instruments with area data, particularly these with stable mathematical formulations. Area knowledge-inspired studying strategies are more likely to be extra data-efficient. As planning transitions from rule-based to ML-based programs, even with early prototypes and merchandise of end-to-end programs hitting the street, there’s a want for engineers who can deeply perceive each the basics of planning and machine studying. Regardless of these adjustments, classical and studying strategies will probably proceed to coexist for a substantial interval, maybe shifting from an 8:2 to a 2:8 ratio. It’s virtually important for engineers working on this subject to know each worlds.
From a value-driven improvement perspective, understanding the constraints of classical strategies is essential. This perception lets you successfully make the most of new ML instruments to design a system that addresses present points and delivers quick impression.
Moreover, planning is a vital a part of all autonomous brokers, not simply in autonomous driving. Understanding what planning is and the way it works will allow extra ML abilities to work on this thrilling matter and contribute to the event of actually autonomous brokers, whether or not they’re vehicles or different types of automation.
What’s planning?
The issue formulation
Because the “mind” of autonomous autos, the planning system is essential for the protected and environment friendly driving of autos. The purpose of the planner is to generate trajectories which can be protected, comfy, and effectively progressing in the direction of the purpose. In different phrases, security, consolation, and effectivity are the three key targets for planning.
As enter to the planning programs, all notion outputs are required, together with static street constructions, dynamic street brokers, free house generated by occupancy networks, and visitors wait situations. The planning system should additionally guarantee automobile consolation by monitoring acceleration and jerk for clean trajectories, whereas contemplating interplay and visitors courtesy.
The planning programs generate trajectories within the format of a sequence of waypoints for the ego automobile’s low-level controller to trace. Particularly, these waypoints symbolize the long run positions of the ego automobile at a collection of fastened time stamps. For instance, every level could be 0.4 seconds aside, overlaying an 8-second planning horizon, leading to a complete of 20 waypoints.
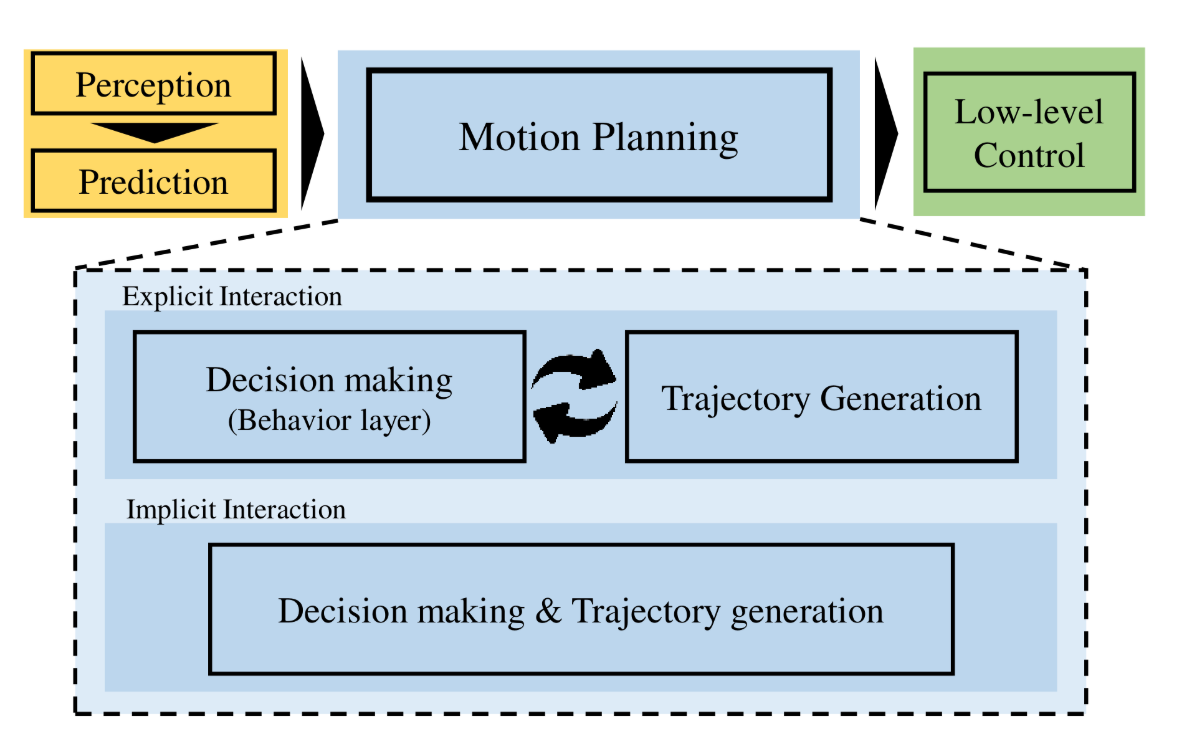
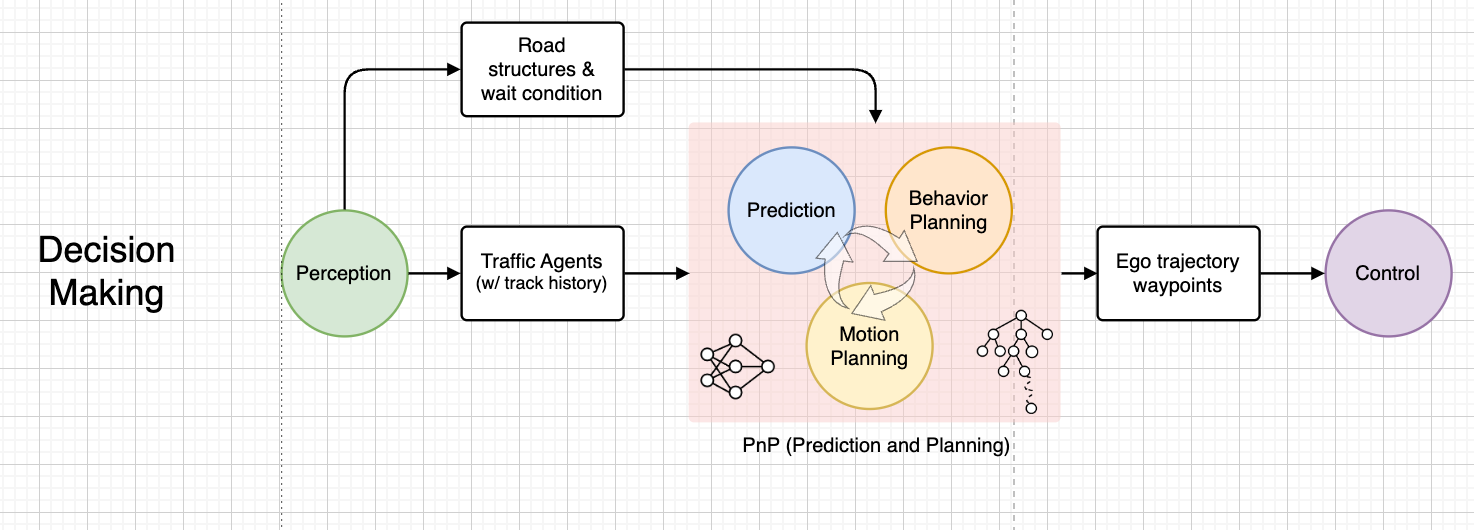
A classical planning stack roughly consists of world route planning, native habits planning, and native trajectory planning. International route planning supplies a road-level path from the beginning level to the tip level on a worldwide map. Native habits planning decides on a semantic driving motion kind (e.g., automobile following, nudging, aspect passing, yielding, and overtaking) for the subsequent a number of seconds. Primarily based on the determined habits kind from the habits planning module, native trajectory planning generates a short-term trajectory. The worldwide route planning is usually offered by a map service as soon as navigation is ready and is past the scope of this put up. We are going to give attention to habits planning and trajectory planning from now on.
Habits planning and trajectory technology can work explicitly in tandem or be mixed right into a single course of. In express strategies, habits planning and trajectory technology are distinct processes working inside a hierarchical framework, working at completely different frequencies, with habits planning at 1–5 Hz and trajectory planning at 10–20 Hz. Regardless of being extremely environment friendly more often than not, adapting to completely different situations might require important modifications and fine-tuning. Extra superior planning programs mix the 2 right into a single optimization drawback. This method ensures feasibility and optimality with none compromise.
The Glossary of Planning
You may need seen that the terminology used within the above part and the picture don’t fully match. There is no such thing as a customary terminology that everybody makes use of. Throughout each academia and business, it’s not unusual for engineers to make use of completely different names to seek advice from the identical idea and the identical title to seek advice from completely different ideas. This means that planning in autonomous driving continues to be underneath energetic improvement and has not totally converged.
Right here, I checklist the notation used on this put up and briefly clarify different notions current within the literature.
- Planning: A top-level idea, parallel to regulate, that generates trajectory waypoints. Collectively, planning and management are collectively known as PnC (planning and management).
- Management: A top-level idea that takes in trajectory waypoints and generates high-frequency steering, throttle, and brake instructions for actuators to execute. Management is comparatively well-established in comparison with different areas and is past the scope of this put up, regardless of the widespread notion of PnC.
- Prediction: A top-level idea that predicts the long run trajectories of visitors brokers aside from the ego automobile. Prediction will be thought-about a light-weight planner for different brokers and can be referred to as movement prediction.
- Habits Planning: A module that produces high-level semantic actions (e.g., lane change, overtake) and usually generates a rough trajectory. Additionally it is often known as activity planning or resolution making, significantly within the context of interactions.
- Movement Planning: A module that takes in semantic actions and produces clean, possible trajectory waypoints at some stage in the planning horizon for management to execute. Additionally it is known as trajectory planning.
- Trajectory Planning: One other time period for movement planning.
- Choice Making: Habits planning with a give attention to interactions. With out ego-agent interplay, it’s merely known as habits planning. Additionally it is often known as tactical resolution making.
- Route Planning: Finds the popular route over street networks, also called mission planning.
- Mannequin-Primarily based Method: In planning, this refers to manually crafted frameworks used within the classical planning stack, versus neural community fashions. Mannequin-based strategies distinction with learning-based strategies.
- Multimodality: Within the context of planning, this usually refers to a number of intentions. This contrasts with multimodality within the context of multimodal sensor inputs to notion or multimodal massive language fashions (akin to VLM or VLA).
- Reference Line: An area (a number of hundred meters) and coarse path primarily based on international routing info and the present state of the ego automobile.
- Frenet Coordinates: A coordinate system primarily based on a reference line. Frenet simplifies a curvy path in Cartesian coordinates to a straight tunnel mannequin. See beneath for a extra detailed introduction.
- Trajectory: A 3D spatiotemporal curve, within the type of (x, y, t) in Cartesian coordinates or (s, l, t) in Frenet coordinates. A trajectory consists of each path and pace.
- Path: A 2D spatial curve, within the type of (x, y) in Cartesian coordinates or (s, l) in Frenet coordinates.
- Semantic Motion: A high-level abstraction of motion (e.g., automobile following, nudge, aspect move, yield, overtake) with clear human intention. Additionally known as intention, coverage, maneuver, or primitive movement.
- Motion: A time period with no fastened that means. It could possibly seek advice from the output of management (high-frequency steering, throttle, and brake instructions for actuators to execute) or the output of planning (trajectory waypoints). Semantic motion refers back to the output of habits prediction.
Completely different literature might use varied notations and ideas. Listed here are some examples:
- Choice Making System: Typically contains planning and management as effectively. (supply: A Survey of Movement Planning and Management Strategies for Self-driving City Automobiles, and BEVGPT)
- Movement Planning: Typically is the top-level planning idea and contains habits planning and trajectory planning. (supply: In the direction of A Common-Goal Movement Planning for Autonomous Automobiles Utilizing Fluid Dynamics).
- Planning: Typically contains habits planning, movement planning, and in addition route planning.
These variations illustrate the variety in terminology and the evolving nature of the subject.
Habits Planning
As a machine studying engineer, you might discover that the habits planning module is a closely manually crafted intermediate module. There is no such thing as a consensus on the precise type and content material of its output. Concretely, the output of habits planning could be a reference path or object labeling on ego maneuvers (e.g., move from the left or right-hand aspect, move or yield). The time period “semantic motion” has no strict definition and no fastened strategies.
The decoupling of habits planning and movement planning will increase effectivity in fixing the extraordinarily high-dimensional motion house of autonomous autos. The actions of an autonomous automobile have to be reasoned at usually 10 Hz or extra (time decision in waypoints), and most of those actions are comparatively simple, like going straight. After decoupling, the habits planning layer solely must cause about future situations at a comparatively coarse decision, whereas the movement planning layer operates within the native answer house primarily based on the choice made by habits planning. One other good thing about habits planning is changing non-convex optimization to convex optimization, which we are going to talk about additional beneath.
Frenet vs Cartesian programs
The Frenet coordinate system is a broadly adopted system that deserves its personal introduction part. The Frenet body simplifies trajectory planning by independently managing lateral and longitudinal actions relative to a reference path. The sss coordinate represents longitudinal displacement (distance alongside the street), whereas the lll (or ddd) coordinate represents lateral displacement (aspect place relative to the reference path).
Frenet simplifies a curvy path in Cartesian coordinates to a straight tunnel mannequin. This transformation converts non-linear street boundary constraints on curvy roads into linear ones, considerably simplifying the next optimization issues. Moreover, people understand longitudinal and lateral actions in another way, and the Frenet body permits for separate and extra versatile optimization of those actions.
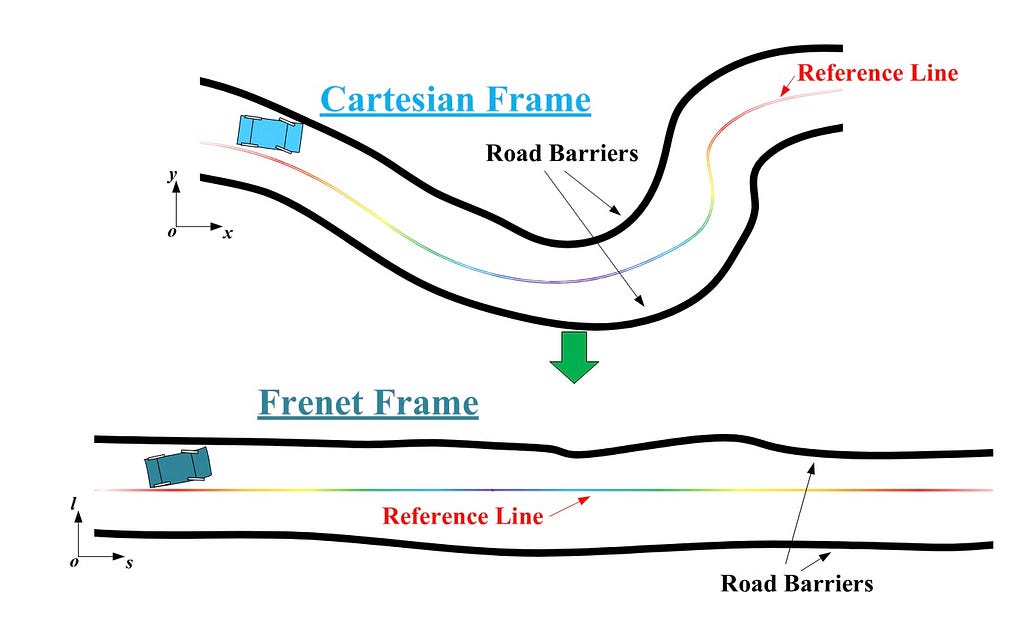
The Frenet coordinate system requires a clear, structured street graph with low curvature lanes. In observe, it’s most popular for structured roads with small curvature, akin to highways or metropolis expressways. Nonetheless, the problems with the Frenet coordinate system are amplified with rising reference line curvature, so it ought to be used cautiously on structured roads with excessive curvature, like metropolis intersections with information traces.
For unstructured roads, akin to ports, mining areas, parking heaps, or intersections with out pointers, the extra versatile Cartesian coordinate system is advisable. The Cartesian system is best fitted to these environments as a result of it could possibly deal with greater curvature and fewer structured situations extra successfully.
Classical instruments — the troika of planning
Planning in autonomous driving includes computing a trajectory from an preliminary high-dimensional state (together with place, time, velocity, acceleration, and jerk) to a goal subspace, making certain all constraints are glad. Looking, sampling, and optimization are the three most generally used instruments for planning.
Looking
Classical graph-search strategies are common in planning and are utilized in route/mission planning on structured roads or straight in movement planning to search out the most effective path in unstructured environments (akin to parking or city intersections, particularly mapless situations). There’s a clear evolution path, from Dijkstra’s algorithm to A* (A-star), and additional to hybrid A*.
Dijkstra’s algorithm explores all attainable paths to search out the shortest one, making it a blind (uninformed) search algorithm. It’s a systematic methodology that ensures the optimum path, however it’s inefficient to deploy. As proven within the chart beneath, it explores virtually all instructions. Primarily, Dijkstra’s algorithm is a breadth-first search (BFS) weighted by motion prices. To enhance effectivity, we are able to use details about the placement of the goal to trim down the search house.
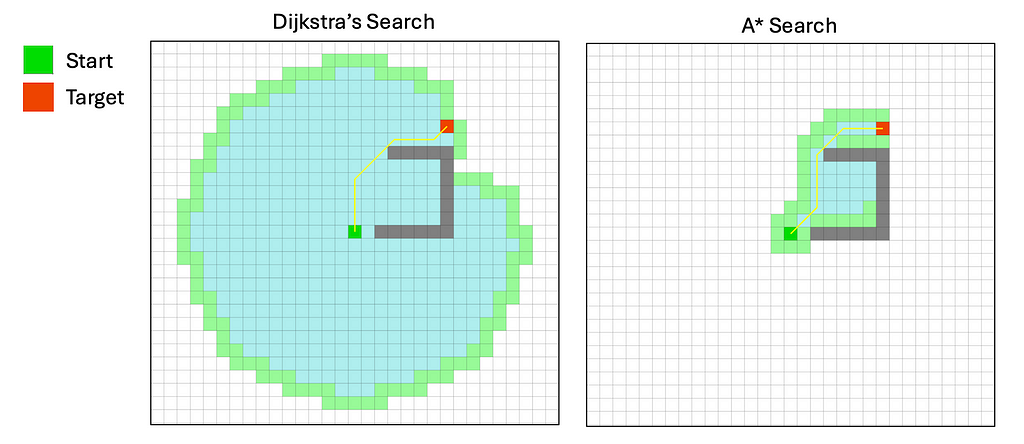
The A* algorithm makes use of heuristics to prioritize paths that seem like main nearer to the purpose, making it extra environment friendly. It combines the price to date (Dijkstra) with the price to go (heuristics, primarily grasping best-first). A* solely ensures the shortest path if the heuristic is admissible and constant. If the heuristic is poor, A* can carry out worse than the Dijkstra baseline and will degenerate right into a grasping best-first search.
Within the particular software of autonomous driving, the hybrid A* algorithm additional improves A* by contemplating automobile kinematics. A* might not fulfill kinematic constraints and can’t be tracked precisely (e.g., the steering angle is usually inside 40 levels). Whereas A* operates in grid house for each state and motion, hybrid A* separates them, sustaining the state within the grid however permitting steady motion in line with kinematics.
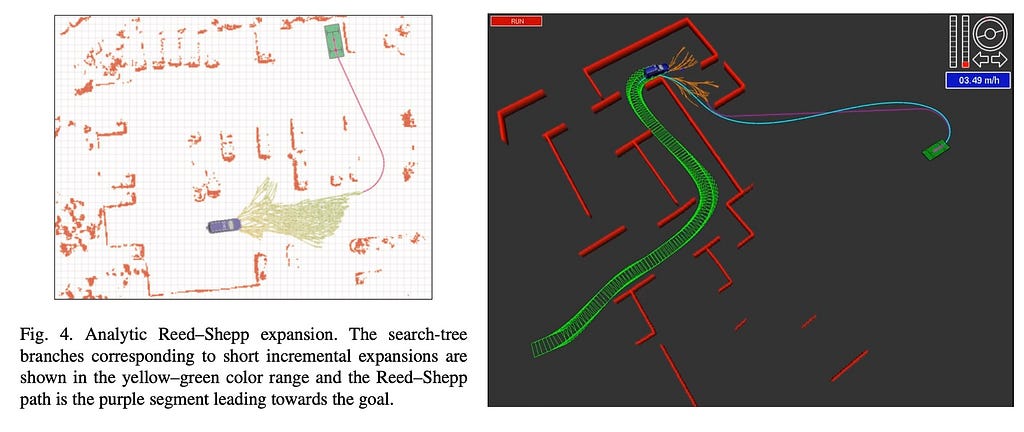
Analytical growth (shot to purpose) is one other key innovation proposed by hybrid A*. A pure enhancement to A* is to attach probably the most not too long ago explored nodes to the purpose utilizing a non-colliding straight line. If that is attainable, we have now discovered the answer. In hybrid A*, this straight line is changed by Dubins and Reeds-Shepp (RS) curves, which adjust to automobile kinematics. This early stopping methodology strikes a steadiness between optimality and feasibility by focusing extra on feasibility for the additional aspect.
Hybrid A* is used closely in parking situations and mapless city intersections. Here’s a very good video showcasing the way it works in a parking situation.
Sampling
One other common methodology of planning is sampling. The well-known Monte Carlo methodology is a random sampling methodology. In essence, sampling includes choosing many candidates randomly or in line with a previous, after which selecting the right one in line with an outlined value. For sampling-based strategies, the quick analysis of many choices is vital, because it straight impacts the real-time efficiency of the autonomous driving system.
Massive Language Fashions (LLMs) primarily present samples, and there must be an evaluator with an outlined value that aligns with human preferences. This analysis course of ensures that the chosen output meets the specified standards and high quality requirements.
Sampling can happen in a parameterized answer house if we already know the analytical answer to a given drawback or subproblem. For instance, usually we wish to reduce the time integral of the sq. of jerk (the third by-product of place p(t)), indicated by the triple dots over p, the place one dot represents one order by-product with respect to time), amongst different standards.
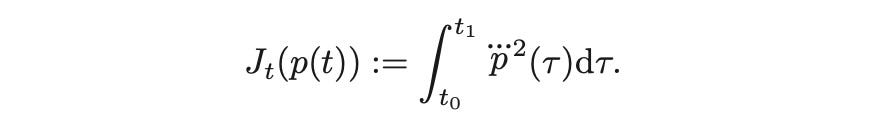
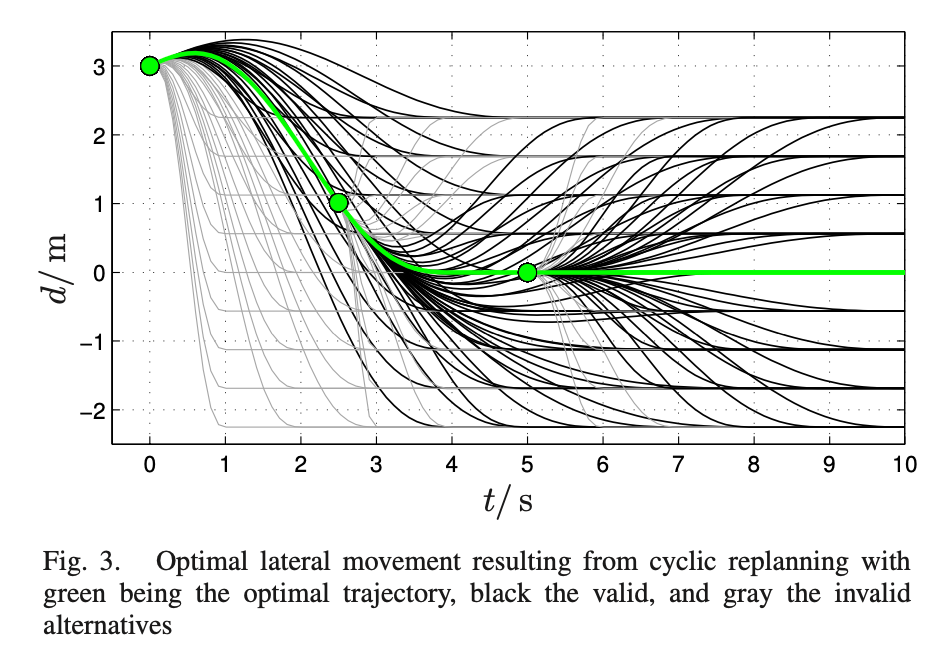
It may be mathematically confirmed that quintic (fifth order) polynomials present the jerk-optimal connection between two states in a position-velocity-acceleration house, even when extra value phrases are thought-about. By sampling on this parameter house of quintic polynomials, we are able to discover the one with the minimal value to get the approximate answer. The fee takes under consideration components akin to pace, acceleration, jerk restrict, and collision checks. This method primarily solves the optimization drawback by means of sampling.
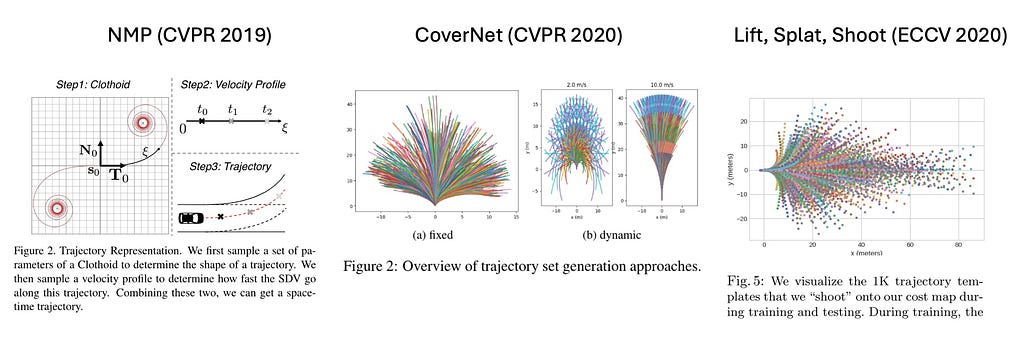
Sampling-based strategies have impressed quite a few ML papers, together with CoverNet, Elevate-Splat-Shoot, NMP, and MP3. These strategies exchange mathematically sound quintic polynomials with human driving habits, using a big database. The analysis of trajectories will be simply parallelized, which additional helps the usage of sampling-based strategies. This method successfully leverages an unlimited quantity of knowledgeable demonstrations to imitate human-like driving habits, whereas avoiding random sampling of acceleration and steering profiles.
Optimization
Optimization finds the most effective answer to an issue by maximizing or minimizing a particular goal perform underneath given constraints. In neural community coaching, an analogous precept is adopted utilizing gradient descent and backpropagation to regulate the community’s weights. Nonetheless, in optimization duties exterior of neural networks, fashions are often much less complicated, and simpler strategies than gradient descent are sometimes employed. For instance, whereas gradient descent will be utilized to Quadratic Programming, it’s usually not probably the most environment friendly methodology.
In autonomous driving, the planning value to optimize usually considers dynamic objects for impediment avoidance, static street constructions for following lanes, navigation info to make sure the right route, and ego standing to guage smoothness.
Optimization will be categorized into convex and non-convex sorts. The important thing distinction is that in a convex optimization situation, there is just one international optimum, which can be the native optimum. This attribute makes it unaffected by the preliminary answer to the optimization issues. For non-convex optimization, the preliminary answer issues loads, as illustrated within the chart beneath.
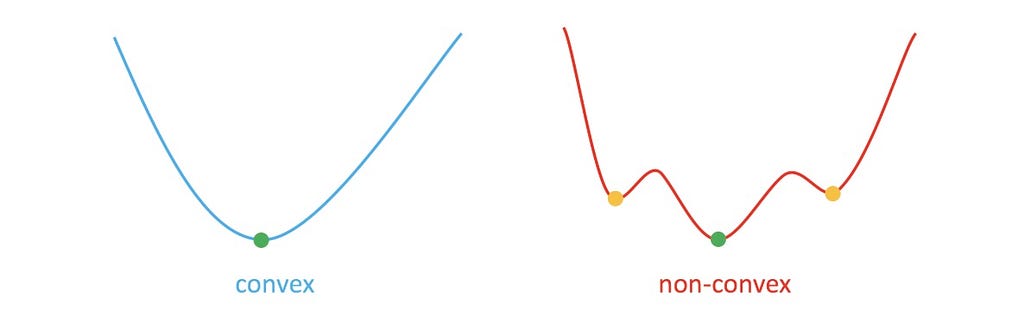
Since planning includes extremely non-convex optimization with many native optima, it closely relies on the preliminary answer. Moreover, convex optimization usually runs a lot quicker and is subsequently most popular for onboard real-time purposes akin to autonomous driving. A typical method is to make use of convex optimization at the side of different strategies to stipulate a convex answer house first. That is the mathematical basis behind separating habits planning and movement planning, the place discovering an excellent preliminary answer is the function of habits planning.
Take impediment avoidance as a concrete instance, which generally introduces non-convex issues. If we all know the nudging route, then it turns into a convex optimization drawback, with the impediment place appearing as a decrease or higher certain constraint for the optimization drawback. If we don’t know the nudging route, we have to resolve first which route to nudge, making the issue a convex one for movement planning to unravel. This nudging route resolution falls underneath habits planning.
In fact, we are able to do direct optimization of non-convex optimization issues with instruments akin to projected gradient descent, alternating minimization, particle swarm optimization (PSO), and genetic algorithms. Nonetheless, that is past the scope of this put up.
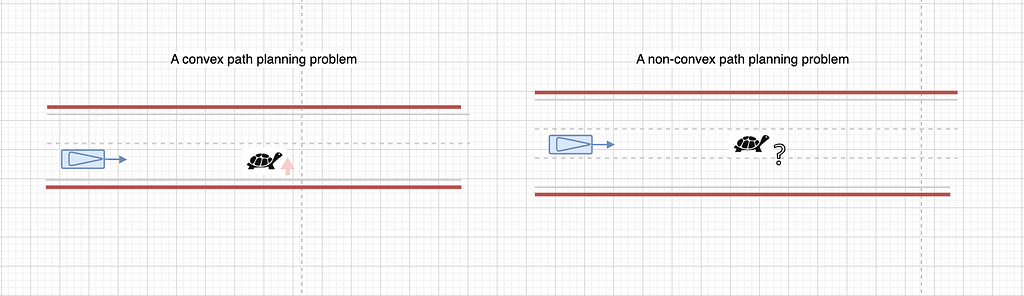
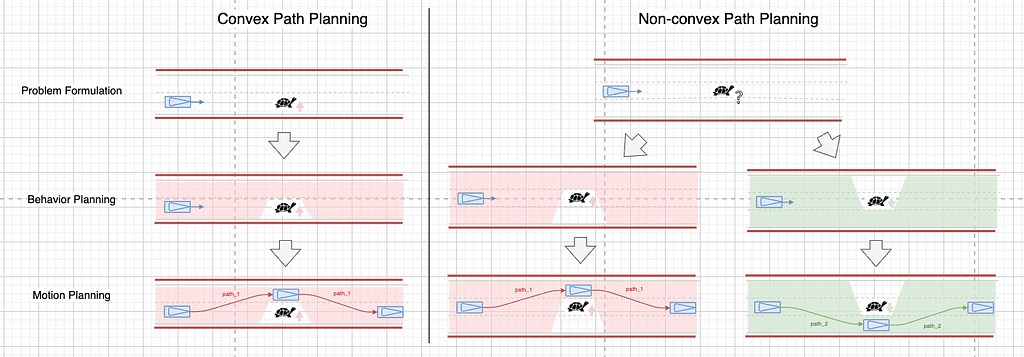
How will we make such choices? We will use the aforementioned search or sampling strategies to handle non-convex issues. Sampling-based strategies scatter many choices throughout the parameter house, successfully dealing with non-convex points equally to looking out.
You might also query why deciding which route to nudge from is sufficient to assure the issue house is convex. To clarify this, we have to talk about topology. In path house, related possible paths can rework constantly into one another with out impediment interference. These related paths, grouped as “homotopy lessons” within the formal language of topology, can all be explored utilizing a single preliminary answer homotopic to them. All these paths type a driving hall, illustrated because the crimson or inexperienced shaded space within the picture above. For a 3D spatiotemporal case, please seek advice from the QCraft tech weblog.
We will make the most of the Generalized Voronoi diagram to enumerate all homotopy lessons, which roughly corresponds to the completely different resolution paths obtainable to us. Nonetheless, this matter delves into superior mathematical ideas which can be past the scope of this weblog put up.
The important thing to fixing optimization issues effectively lies within the capabilities of the optimization solver. Sometimes, a solver requires roughly 10 milliseconds to plan a trajectory. If we are able to enhance this effectivity by tenfold, it could possibly considerably impression algorithm design. This precise enchancment was highlighted throughout Tesla AI Day 2022. An analogous enhancement has occurred in notion programs, transitioning from 2D notion to Fowl’s Eye View (BEV) as obtainable computing energy scaled up tenfold. With a extra environment friendly optimizer, extra choices will be calculated and evaluated, thereby decreasing the significance of the decision-making course of. Nonetheless, engineering an environment friendly optimization solver calls for substantial engineering sources.
Each time compute scales up by 10x, algorithm will evolve to subsequent technology.
— — The unverified regulation of algorithm evolution
Business Practices of Planning
A key differentiator in varied planning programs is whether or not they’re spatiotemporally decoupled. Concretely, spatiotemporally decoupled strategies plan in spatial dimensions first to generate a path, after which plan the pace profile alongside this path. This method is also called path-speed decoupling.
Path-speed decoupling is sometimes called lateral-longitudinal (lat-long) decoupling, the place lateral (lat) planning corresponds to path planning and longitudinal (lengthy) planning corresponds to hurry planning. This terminology appears to originate from the Frenet coordinate system, which we are going to discover later.
Decoupled options are simpler to implement and might resolve about 95% of points. In distinction, coupled options have the next theoretical efficiency ceiling however are tougher to implement. They contain extra parameters to tune and require a extra principled method to parameter tuning.
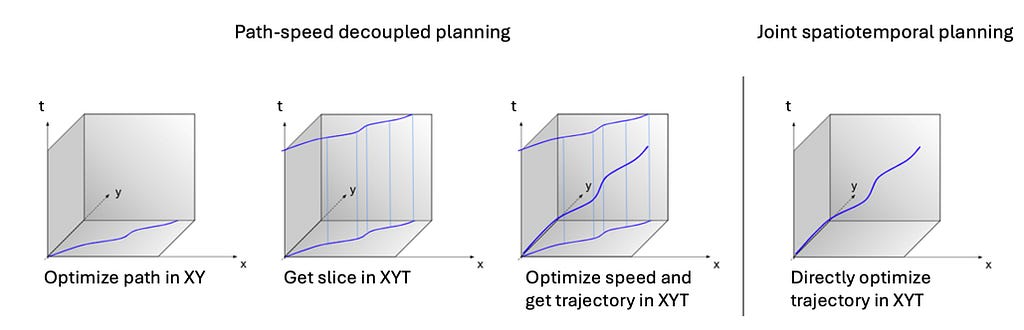

Path-speed decoupled planning
We will take Baidu Apollo EM planner for example of a system that makes use of path-speed decoupled planning.
The EM planner considerably reduces computational complexity by reworking a three-dimensional station-lateral-speed drawback into two two-dimensional issues: station-lateral and station-speed. On the core of Apollo’s EM planner is an iterative Expectation-Maximization (EM) step, consisting of path optimization and pace optimization. Every step is split into an E-step (projection and formulation in a 2D state house) and an M-step (optimization within the 2D state house). The E-step includes projecting the 3D drawback into both a Frenet SL body or an ST pace monitoring body.
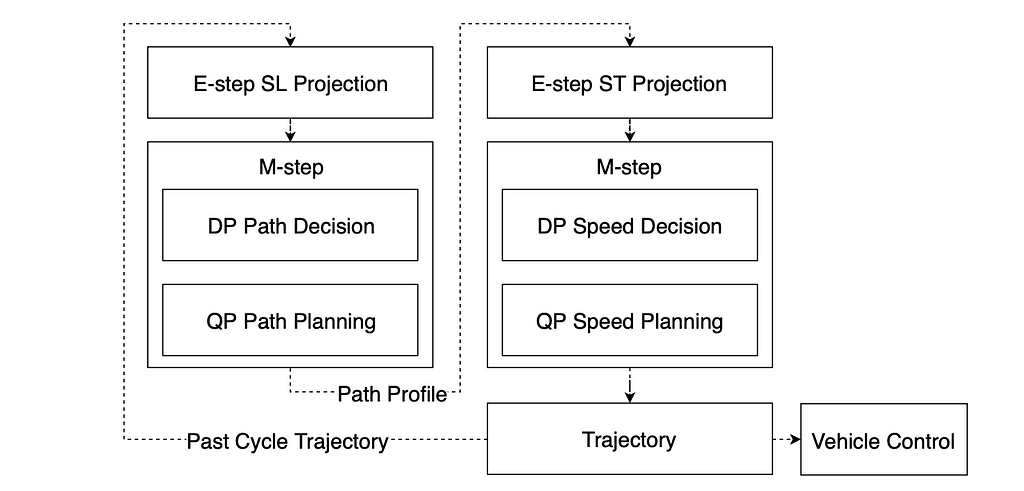
The M-step (maximization step) in each path and pace optimization includes fixing non-convex optimization issues. For path optimization, this implies deciding whether or not to nudge an object on the left or proper aspect, whereas for pace optimization, it includes deciding whether or not to overhaul or yield to a dynamic object crossing the trail. The Apollo EM planner addresses these non-convex optimization challenges utilizing a two-step course of: Dynamic Programming (DP) adopted by Quadratic Programming (QP).
DP makes use of a sampling or looking out algorithm to generate a tough preliminary answer, successfully pruning the non-convex house right into a convex house. QP then takes the coarse DP outcomes as enter and optimizes them inside the convex house offered by DP. In essence, DP focuses on feasibility, and QP refines the answer to realize optimality inside the convex constraints.
In our outlined terminology, Path DP corresponds to lateral BP, Path QP to lateral MP, Velocity DP to longitudinal BP, and Velocity QP to longitudinal MP. Thus, the method includes conducting BP (Fundamental Planning) adopted by MP (Grasp Planning) in each the trail and pace steps.
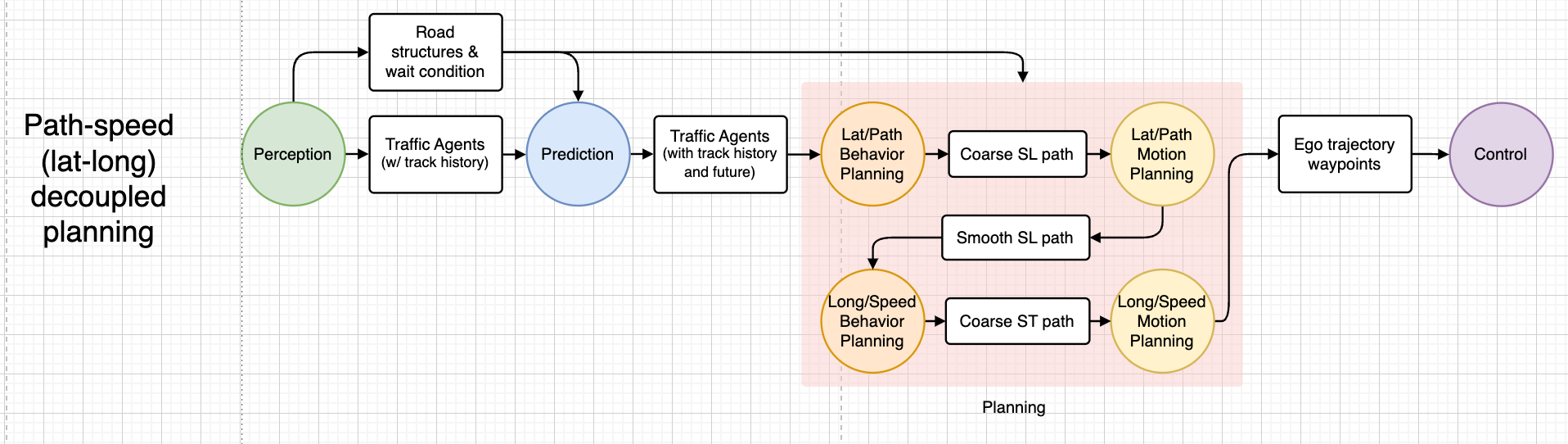
Joint spatiotemporal planning
Though decoupled planning can resolve 95% of instances in autonomous driving, the remaining 5% contain difficult dynamic interactions the place a decoupled answer typically ends in suboptimal trajectories. In these complicated situations, demonstrating intelligence is essential, making it a very popular matter within the subject.
For instance, in narrow-space passing, the optimum habits could be to both decelerate to yield or speed up to move. Such behaviors usually are not achievable inside the decoupled answer house and require joint optimization. Joint optimization permits for a extra built-in method, contemplating each path and pace concurrently to deal with intricate dynamic interactions successfully.

Nonetheless, there are important challenges in joint spatiotemporal planning. Firstly, fixing the non-convex drawback straight in a higher-dimensional state house is tougher and time-consuming than utilizing a decoupled answer. Secondly, contemplating interactions in spatiotemporal joint planning is much more complicated. We are going to cowl this matter in additional element later once we talk about decision-making.
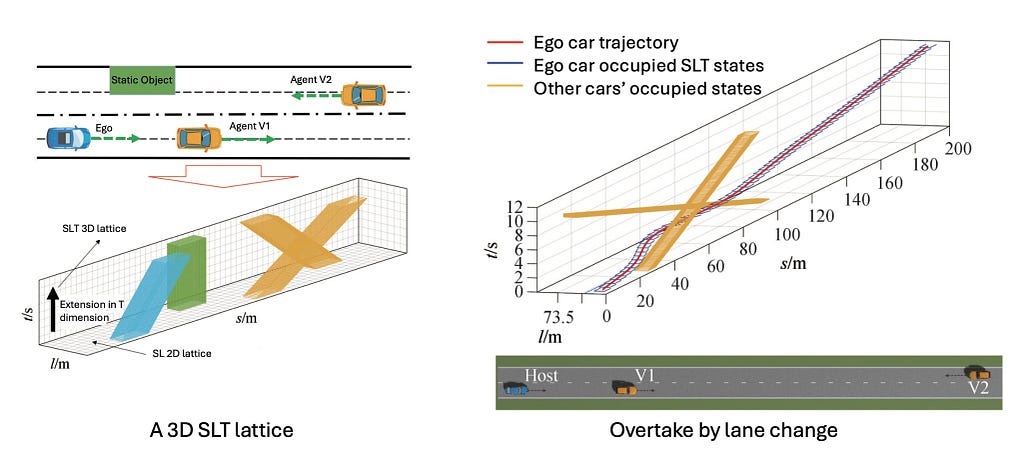
Right here we introduce two fixing strategies: brute power search and setting up a spatiotemporal hall for optimization.
Brute power search happens straight in 3D spatiotemporal house (2D in house and 1D in time), and will be carried out in both XYT (Cartesian) or SLT (Frenet) coordinates. We are going to take SLT for example. SLT house is lengthy and flat, much like an vitality bar. It’s elongated within the L dimension and flat within the ST face. For brute power search, we are able to use hybrid A-star, with the price being a mixture of progress value and price to go. Throughout optimization, we should conform to look constraints that forestall reversing in each the s and t dimensions.
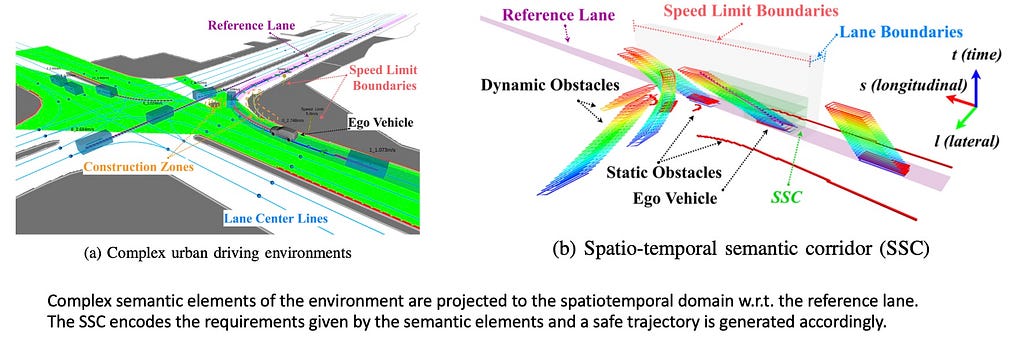
One other methodology is setting up a spatiotemporal hall, primarily a curve with the footprint of a automobile winding by means of a 3D spatiotemporal state house (SLT, for instance). The SSC (spatiotemporal semantic hall, RAL 2019), encodes necessities given by semantic parts right into a semantic hall, producing a protected trajectory accordingly. The semantic hall consists of a collection of mutually linked collision-free cubes with dynamical constraints posed by the semantic parts within the spatiotemporal area. Inside every dice, it turns into a convex optimization drawback that may be solved utilizing Quadratic Programming (QP).
SSC nonetheless requires a BP (Habits Planning) module to offer a rough driving trajectory. Advanced semantic parts of the setting are projected into the spatiotemporal area in regards to the reference lane. EPSILON (TRO 2021), showcases a system the place SSC serves because the movement planner working in tandem with a habits planner. Within the subsequent part, we are going to talk about habits planning, particularly specializing in interplay. On this context, habits planning is often known as resolution making.
Choice making
What and why?
Choice making in autonomous driving is basically habits planning, however with a give attention to interplay with different visitors brokers. The idea is that different brokers are largely rational and can reply to our habits in a predictable method, which we are able to describe as “noisily rational.”
Folks might query the need of resolution making when superior planning instruments can be found. Nonetheless, two key points — uncertainty and interplay — introduce a probabilistic nature to the setting, primarily because of the presence of dynamic objects. Interplay is probably the most difficult a part of autonomous driving, distinguishing it from normal robotics. Autonomous autos should not solely navigate but additionally anticipate and react to the habits of different brokers, making sturdy decision-making important for security and effectivity.
In a deterministic (purely geometric) world with out interplay, resolution making can be pointless, and planning by means of looking out, sampling, and optimization would suffice. Brute power looking out within the 3D XYT house may function a normal answer.
In most classical autonomous driving stacks, a prediction-then-plan method is adopted, assuming zero-order interplay between the ego automobile and different autos. This method treats prediction outputs as deterministic, requiring the ego automobile to react accordingly. This results in overly conservative habits, exemplified by the “freezing robotic” drawback. In such instances, prediction fills your complete spatiotemporal house, stopping actions like lane adjustments in crowded situations — one thing people handle extra successfully.
To deal with stochastic methods, Markov Choice Processes (MDP) or Partially Observable Markov Choice Processes (POMDP) frameworks are important. These approaches shift the main focus from geometry to likelihood, addressing chaotic uncertainty. By assuming that visitors brokers behave rationally or a minimum of noisily rationally, resolution making will help create a protected driving hall within the in any other case chaotic spatiotemporal house.
Among the many three overarching targets of planning — security, consolation, and effectivity — resolution making primarily enhances effectivity. Conservative actions can maximize security and luxury, however efficient negotiation with different street brokers, achievable by means of resolution making, is crucial for optimum effectivity. Efficient resolution making additionally shows intelligence.
MDP and POMDP
We are going to first introduce Markov Choice Processes (MDP) and Partially Observable Markov Choice Processes (POMDP), adopted by their systematic options, akin to worth iteration and coverage iteration.
A Markov Course of (MP) is a kind of stochastic course of that offers with dynamic random phenomena, in contrast to static likelihood. In a Markov Course of, the long run state relies upon solely on the present state, making it ample for prediction. For autonomous driving, the related state might solely embody the final second of information, increasing the state house to permit for a shorter historical past window.
A Markov Choice Course of (MDP) extends a Markov Course of to incorporate decision-making by introducing motion. MDPs mannequin decision-making the place outcomes are partly random and partly managed by the choice maker or agent. An MDP will be modeled with 5 components:
- State (S): The state of the setting.
- Motion (A): The actions the agent can take to have an effect on the setting.
- Reward (R): The reward the setting supplies to the agent on account of the motion.
- Transition Chance (P): The likelihood of transitioning from the outdated state to a brand new state upon the agent’s motion.
- Gamma (γ): A reduction issue for future rewards.
That is additionally the widespread framework utilized by reinforcement studying (RL), which is basically an MDP. The purpose of MDP or RL is to maximise the cumulative reward obtained in the long term. This requires the agent to make good choices given a state from the setting, in line with a coverage.
A coverage, π, is a mapping from every state, s ∈ S, and motion, a ∈ A(s), to the likelihood π(a|s) of taking motion a when in state s. MDP or RL research the issue of tips on how to derive the optimum coverage.
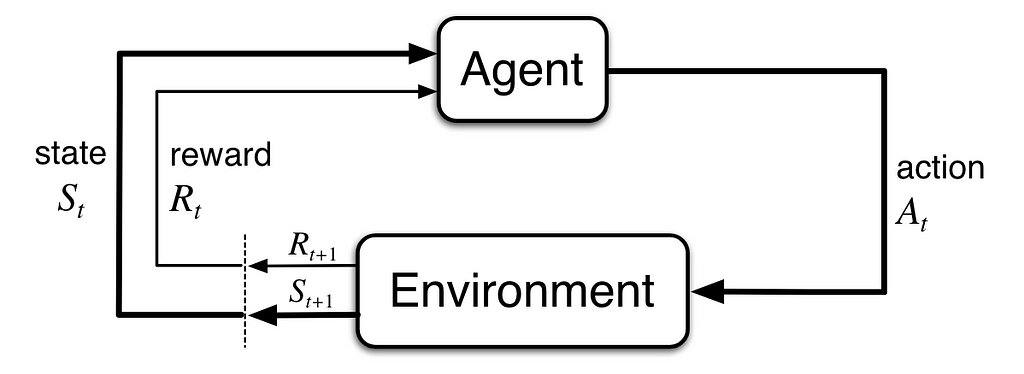
A Partially Observable Markov Choice Course of (POMDP) provides an additional layer of complexity by recognizing that states can’t be straight noticed however moderately inferred by means of observations. In a POMDP, the agent maintains a perception — a likelihood distribution over attainable states — to estimate the state of the setting. Autonomous driving situations are higher represented by POMDPs because of their inherent uncertainties and the partial observability of the setting. An MDP will be thought-about a particular case of a POMDP the place the statement completely reveals the state.
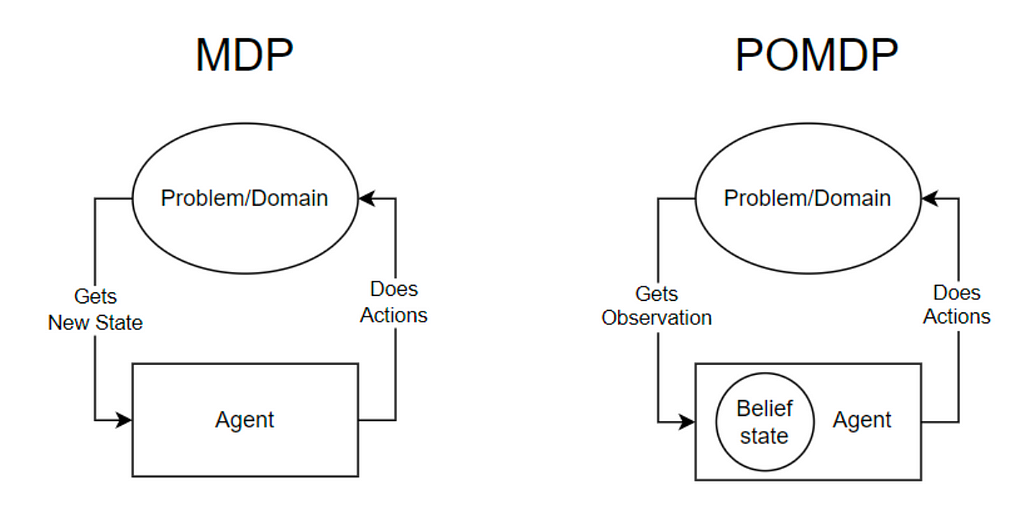
POMDPs can actively acquire info, resulting in actions that collect mandatory information, demonstrating the clever habits of those fashions. This functionality is especially useful in situations like ready at intersections, the place gathering details about different autos’ intentions and the state of the visitors gentle is essential for making protected and environment friendly choices.
Worth iteration and Coverage iteration
Worth iteration and coverage iteration are systematic strategies for fixing MDP or POMDP issues. Whereas these strategies usually are not generally utilized in real-world purposes because of their complexity, understanding them supplies perception into precise options and the way they are often simplified in observe, akin to utilizing MCTS in AlphaGo or MPDM in autonomous driving.
To seek out the most effective coverage in an MDP, we should assess the potential or anticipated reward from a state, or extra particularly, from an motion taken in that state. This anticipated reward contains not simply the quick reward but additionally all future rewards, formally often known as the return or cumulative discounted reward. (For a deeper understanding, seek advice from “Reinforcement Studying: An Introduction,” typically thought-about the definitive information on the topic.)
The worth perform (V) characterizes the standard of states by summing the anticipated returns. The action-value perform (Q) assesses the standard of actions for a given state. Each features are outlined in line with a given coverage. The Bellman Optimality Equation states that an optimum coverage will select the motion that maximizes the quick reward plus the anticipated future rewards from the ensuing new states. In easy phrases, the Bellman Optimality Equation advises contemplating each the quick reward and the long run penalties of an motion. For instance, when switching jobs, think about not solely the quick pay increase (R) but additionally the long run worth (S’) the brand new place presents.
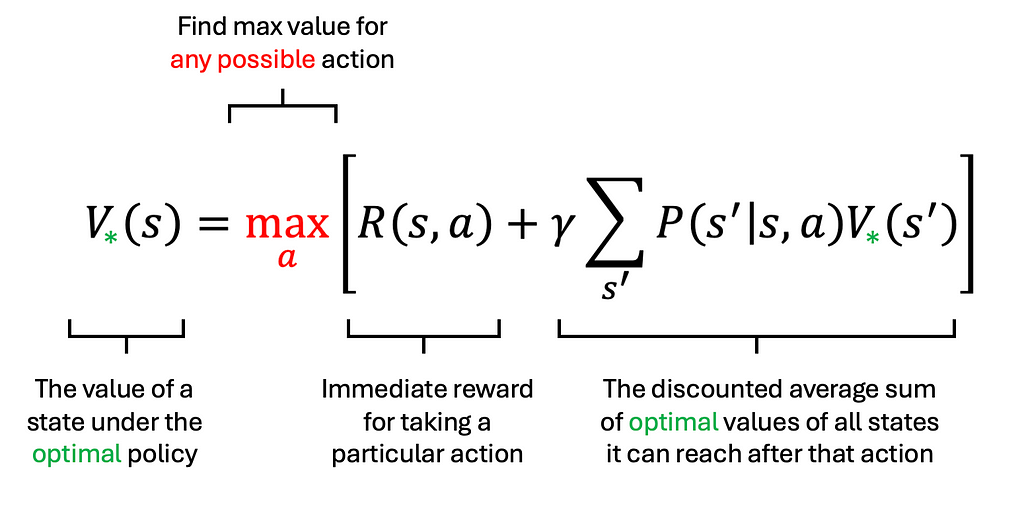
It’s comparatively simple to extract the optimum coverage from the Bellman Optimality Equation as soon as the optimum worth perform is accessible. However how do we discover this optimum worth perform? That is the place worth iteration involves the rescue.
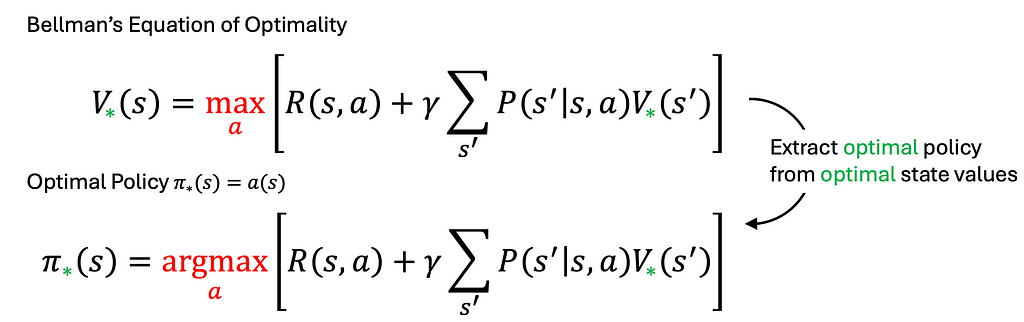
Worth iteration finds the most effective coverage by repeatedly updating the worth of every state till it stabilizes. This course of is derived by turning the Bellman Optimality Equation into an replace rule. Primarily, we use the optimum future image to information the iteration towards it. In plain language, “faux it till you make it!”
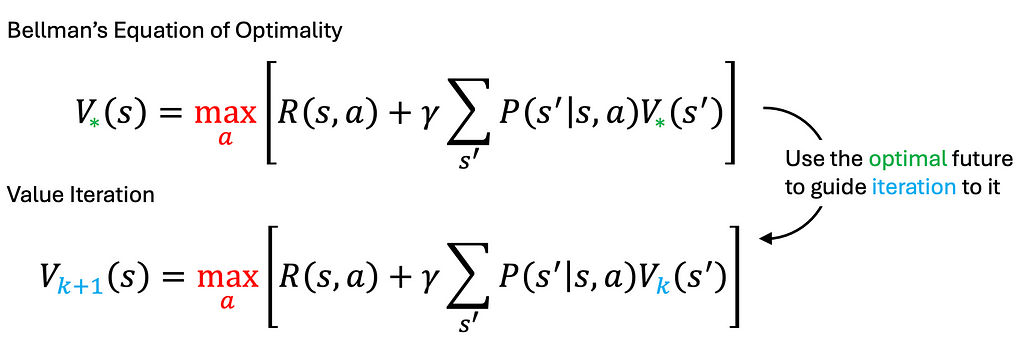
Worth iteration is assured to converge for finite state areas, whatever the preliminary values assigned to the states (for an in depth proof, please seek advice from the Bible of RL). If the low cost issue gamma is ready to 0, that means we solely think about quick rewards, the worth iteration will converge after only one iteration. A smaller gamma results in quicker convergence as a result of the horizon of consideration is shorter, although it might not all the time be the best choice for fixing concrete issues. Balancing the low cost issue is a key facet of engineering observe.
One may ask how this works if all states are initialized to zero. The quick reward within the Bellman Equation is essential for bringing in extra info and breaking the preliminary symmetry. Take into consideration the states that instantly result in the purpose state; their worth propagates by means of the state house like a virus. In plain language, it’s about making small wins, often.
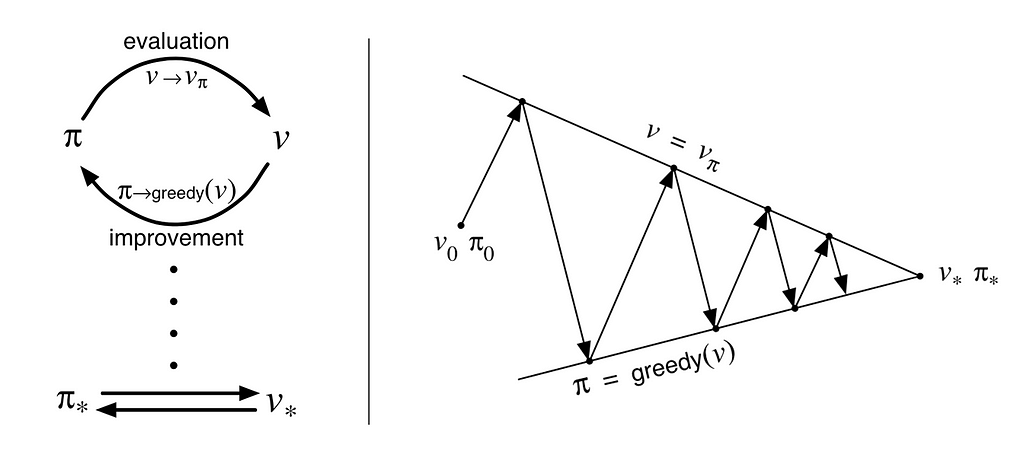
Nonetheless, worth iteration additionally suffers from inefficiency. It requires taking the optimum motion at every iteration by contemplating all attainable actions, much like Dijkstra’s algorithm. Whereas it demonstrates feasibility as a fundamental method, it’s usually not sensible for real-world purposes.
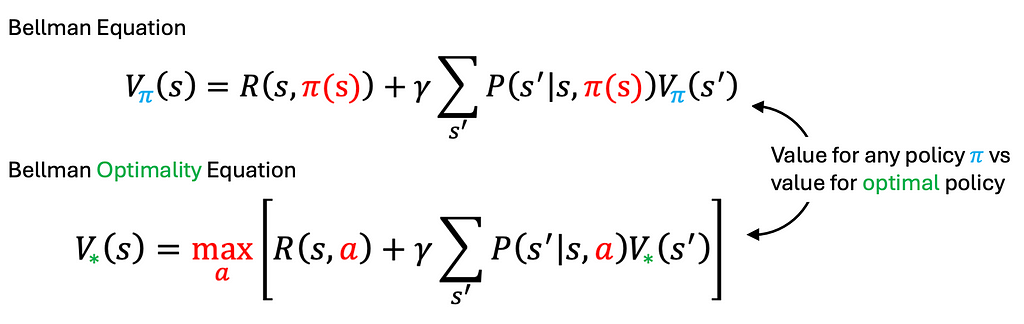
Coverage iteration improves on this by taking actions in line with the present coverage and updating it primarily based on the Bellman Equation (not the Bellman Optimality Equation). Coverage iteration decouples coverage analysis from coverage enchancment, making it a a lot quicker answer. Every step is taken primarily based on a given coverage as a substitute of exploring all attainable actions to search out the one which maximizes the target. Though every iteration of coverage iteration will be extra computationally intensive because of the coverage analysis step, it usually ends in a quicker convergence general.
In easy phrases, if you happen to can solely totally consider the consequence of 1 motion, it’s higher to make use of your individual judgment and do your greatest with the present info obtainable.
AlphaGo and MCTS — when nets meet bushes
We’ve all heard the unbelievable story of AlphaGo beating the most effective human participant in 2016. AlphaGo formulates the gameplay of Go as an MDP and solves it with Monte Carlo Tree Search (MCTS). However why not use worth iteration or coverage iteration?
Worth iteration and coverage iteration are systematic, iterative strategies that resolve MDP issues. Nonetheless, even with improved coverage iteration, it nonetheless requires performing time-consuming operations to replace the worth of each state. A typical 19×19 Go board has roughly 2e170 attainable states. This huge variety of states makes it intractable to unravel with conventional worth iteration or coverage iteration methods.
AlphaGo and its successors use a Monte Carlo tree search (MCTS) algorithm to search out their strikes, guided by a worth community and a coverage community, skilled on each human and laptop play. Let’s check out vanilla MCTS first.
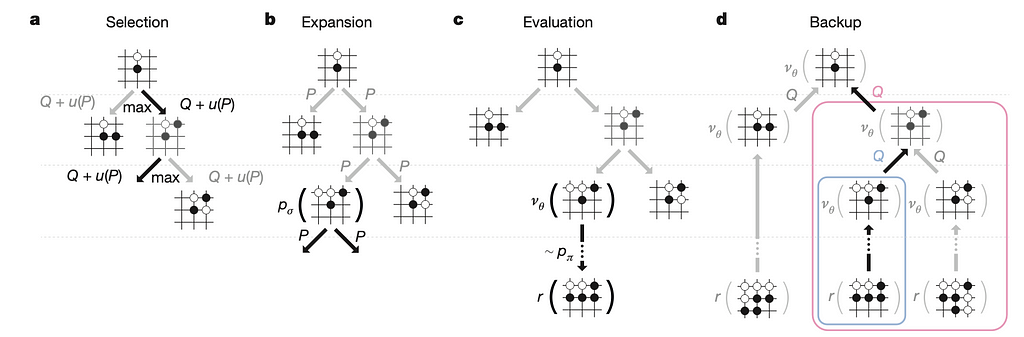
Monte Carlo Tree Search (MCTS) is a technique for coverage estimation that focuses on decision-making from the present state. One iteration includes a four-step course of: choice, growth, simulation (or analysis), and backup.
- Choice: The algorithm follows probably the most promising path primarily based on earlier simulations till it reaches a leaf node, a place not but totally explored.
- Growth: A number of youngster nodes are added to symbolize attainable subsequent strikes from the leaf node.
- Simulation (Analysis): The algorithm performs out a random recreation from the brand new node till the tip, often known as a “rollout.” This assesses the potential final result from the expanded node by simulating random strikes till a terminal state is reached.
- Backup: The algorithm updates the values of the nodes on the trail taken primarily based on the sport’s outcome. If the end result is a win, the worth of the nodes will increase; if it’s a loss, the worth decreases. This course of propagates the results of the rollout again up the tree, refining the coverage primarily based on simulated outcomes.
After a given variety of iterations, MCTS supplies the proportion frequency with which quick actions had been chosen from the basis throughout simulations. Throughout inference, the motion with probably the most visits is chosen. Right here is an interactive illustration of MTCS with the sport of tic-tac-toe for simplicity.
MCTS in AlphaGo is enhanced by two neural networks. Worth Community evaluates the profitable price from a given state (board configuration). Coverage Community evaluates the motion distribution for all attainable strikes. These neural networks enhance MCTS by decreasing the efficient depth and breadth of the search tree. The coverage community helps in sampling actions, focusing the search on promising strikes, whereas the worth community supplies a extra correct analysis of positions, decreasing the necessity for intensive rollouts. This mix permits AlphaGo to carry out environment friendly and efficient searches within the huge state house of Go.
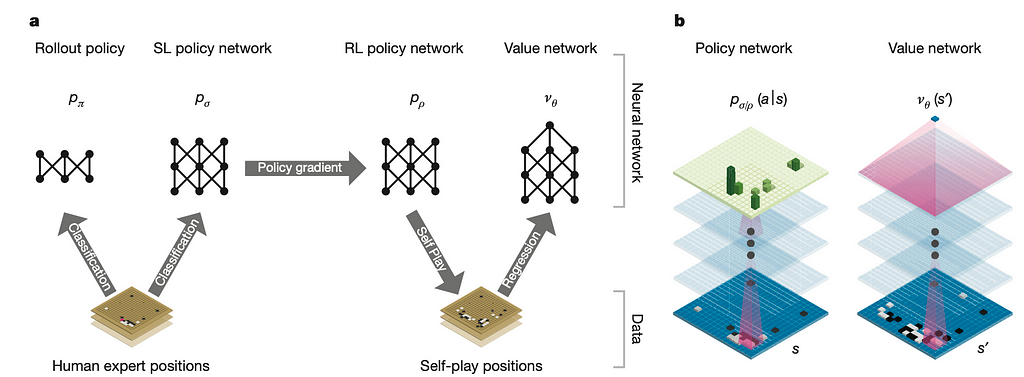
Within the growth step, the coverage community samples the almost definitely positions, successfully pruning the breadth of the search house. Within the analysis step, the worth community supplies an instinctive scoring of the place, whereas a quicker, light-weight coverage community performs rollouts till the sport ends to gather rewards. MCTS then makes use of a weighted sum of the evaluations from each networks to make the ultimate evaluation.
Notice {that a} single analysis of the worth community approaches the accuracy of Monte Carlo rollouts utilizing the RL coverage community however with 15,000 instances much less computation. This mirrors the fast-slow system design, akin to instinct versus reasoning, or System 1 versus System 2 as described by Nobel laureate Daniel Kahneman. Related designs will be noticed in more moderen works, akin to DriveVLM.
To be precise, AlphaGo incorporates two slow-fast programs at completely different ranges. On the macro degree, the coverage community selects strikes whereas the quicker rollout coverage community evaluates these strikes. On the micro degree, the quicker rollout coverage community will be approximated by a worth community that straight predicts the profitable price of board positions.
What can we be taught from AlphaGo for autonomous driving? AlphaGo demonstrates the significance of extracting a superb coverage utilizing a strong world mannequin (simulation). Equally, autonomous driving requires a extremely correct simulation to successfully leverage algorithms much like these utilized by AlphaGo. This method underscores the worth of mixing sturdy coverage networks with detailed, exact simulations to boost decision-making and optimize efficiency in complicated, dynamic environments.
MPDM (and successors) in autonomous driving
Within the recreation of Go, all states are instantly obtainable to each gamers, making it an ideal info recreation the place statement equals state. This enables the sport to be characterised by an MDP course of. In distinction, autonomous driving is a POMDP course of, because the states can solely be estimated by means of statement.
POMDPs join notion and planning in a principled method. The standard answer for a POMDP is much like that for an MDP, with a restricted lookahead. Nonetheless, the principle challenges lie within the curse of dimensionality (explosion in state house) and the complicated interactions with different brokers. To make real-time progress tractable, domain-specific assumptions are usually made to simplify the POMDP drawback.
MPDM (and the two follow-ups, and the white paper) is one pioneering research on this route. MPDM reduces the POMDP to a closed-loop ahead simulation of a finite, discrete set of semantic-level insurance policies, moderately than evaluating each attainable management enter for each automobile. This method addresses the curse of dimensionality by specializing in a manageable variety of significant insurance policies, permitting for efficient real-time decision-making in autonomous driving situations.
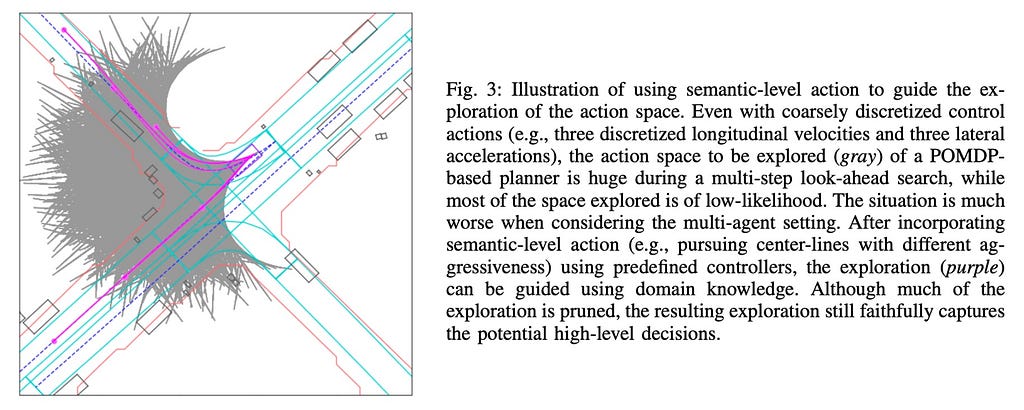
The assumptions of MPDM are twofold. First, a lot of the decision-making by human drivers includes discrete high-level semantic actions (e.g., slowing, accelerating, lane-changing, stopping). These actions are known as insurance policies on this context. The second implicit assumption considerations different brokers: different autos will make moderately protected choices. As soon as a automobile’s coverage is determined, its motion (trajectory) is decided.
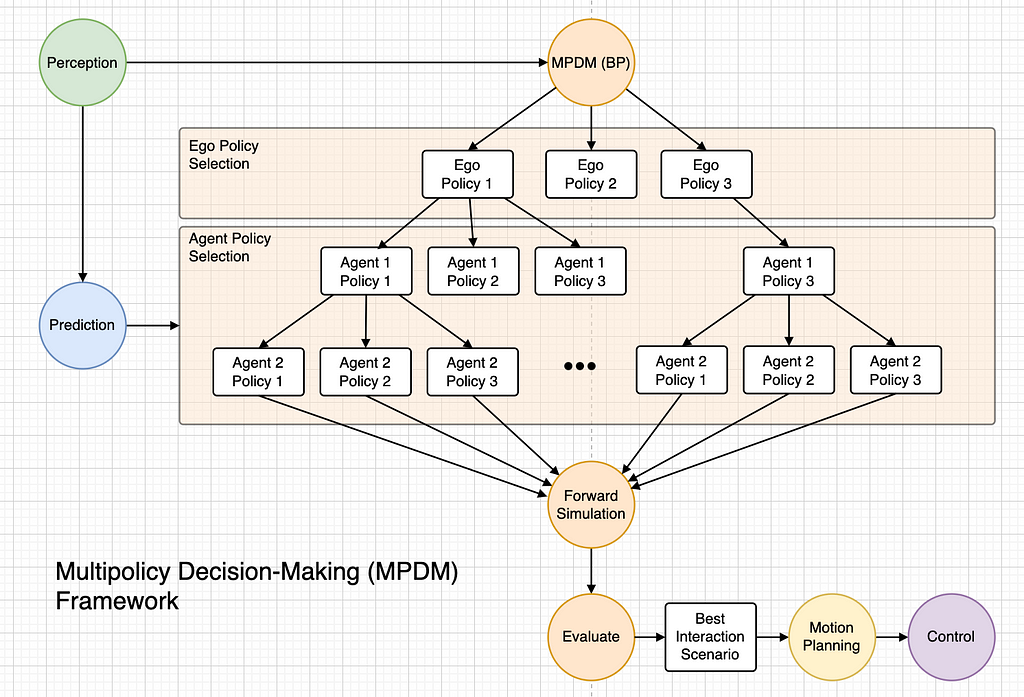
MPDM first selects one coverage for the ego automobile from many choices (therefore the “multi-policy” in its title) and selects one coverage for every close by agent primarily based on their respective predictions. It then performs ahead simulation (much like a quick rollout in MCTS). The very best interplay situation after analysis is then handed on to movement planning, such because the Spatiotemporal Semantic Hall (SCC) talked about within the joint spatiotemporal planning session.
MPDM permits clever and human-like habits, akin to actively slicing into dense visitors circulate even when there isn’t any ample hole current. This isn’t attainable with a predict-then-plan pipeline, which doesn’t explicitly think about interactions. The prediction module in MPDM is tightly built-in with the habits planning mannequin by means of ahead simulation.
MPDM assumes a single coverage all through the choice horizon (10 seconds). Primarily, MPDM adopts an MCTS method with one layer deep and tremendous vast, contemplating all attainable agent predictions. This leaves room for enchancment, inspiring many follow-up works akin to EUDM, EPSILON, and MARC. For instance, EUDM considers extra versatile ego insurance policies and assigns a coverage tree with a depth of 4, with every coverage overlaying a time length of two seconds over an 8-second resolution horizon. To compensate for the additional computation induced by the elevated tree depth, EUDM performs extra environment friendly width pruning by guided branching, figuring out vital situations and key autos. This method explores a extra balanced coverage tree.
The ahead simulation in MPDM and EUDM makes use of very simplistic driver fashions (IDM for longitudinal simulation and Pure Pursuit for lateral simulation). MPDM factors out that top constancy realism issues lower than the closed-loop nature itself, so long as policy-level choices usually are not affected by low-level motion execution inaccuracies.
Contingency planning within the context of autonomous driving includes producing a number of potential trajectories to account for varied attainable future situations. A key motivating instance is that skilled drivers anticipate a number of future situations and all the time plan for a protected backup plan. This anticipatory method results in a smoother driving expertise, even when vehicles carry out sudden cut-ins into the ego lane.
A vital facet of contingency planning is deferring the choice bifurcation level. This implies delaying the purpose at which completely different potential trajectories diverge, permitting the ego automobile extra time to assemble info and reply to completely different outcomes. By doing so, the automobile could make extra knowledgeable choices, leading to smoother and extra assured driving behaviors, much like these of an skilled driver.
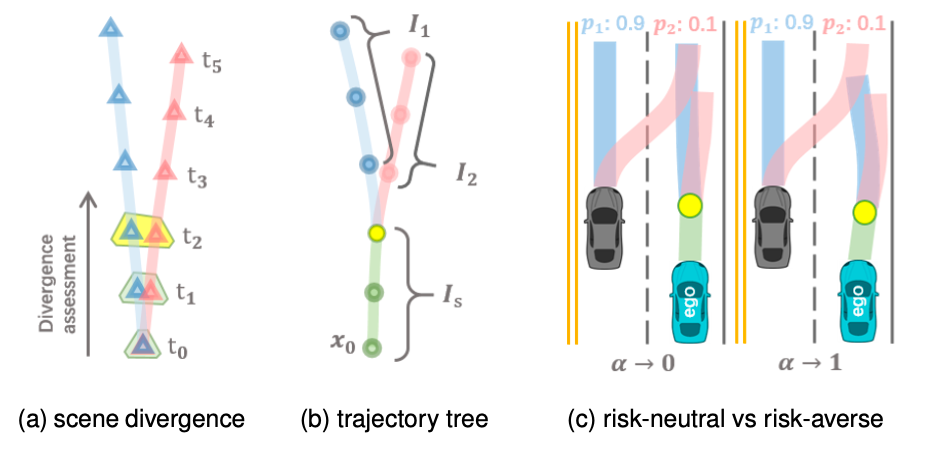
One attainable disadvantage of MPDM and all its follow-up works is their reliance on easy insurance policies designed for highway-like structured environments, akin to lane preserving and lane altering. This reliance might restrict the aptitude of ahead simulation to deal with complicated interactions. To deal with this, following the instance of MPDM, the important thing to creating POMDPs simpler is to simplify the motion and state house by means of the expansion of a high-level coverage tree. It could be attainable to create a extra versatile coverage tree, for instance, by enumerating spatiotemporal relative place tags to all relative objects after which performing guided branching.
Business practices of resolution making
Choice-making stays a sizzling matter in present analysis. Even classical optimization strategies haven’t been totally explored but. Machine studying strategies may shine and have a disruptive impression, particularly with the arrival of Massive Language Fashions (LLMs), empowered by methods like Chain of Thought (CoT) or Monte Carlo Tree Search (MCTS).
Bushes
Bushes are systematic methods to carry out decision-making. Tesla AI Day 2021 and 2022 showcased their decision-making capabilities, closely influenced by AlphaGo and the next MuZero, to handle extremely complicated interactions.
At a excessive degree, Tesla’s method follows habits planning (resolution making) adopted by movement planning. It searches for a convex hall first after which feeds it into steady optimization, utilizing spatiotemporal joint planning. This method successfully addresses situations akin to slender passing, a typical bottleneck for path-speed decoupled planning.
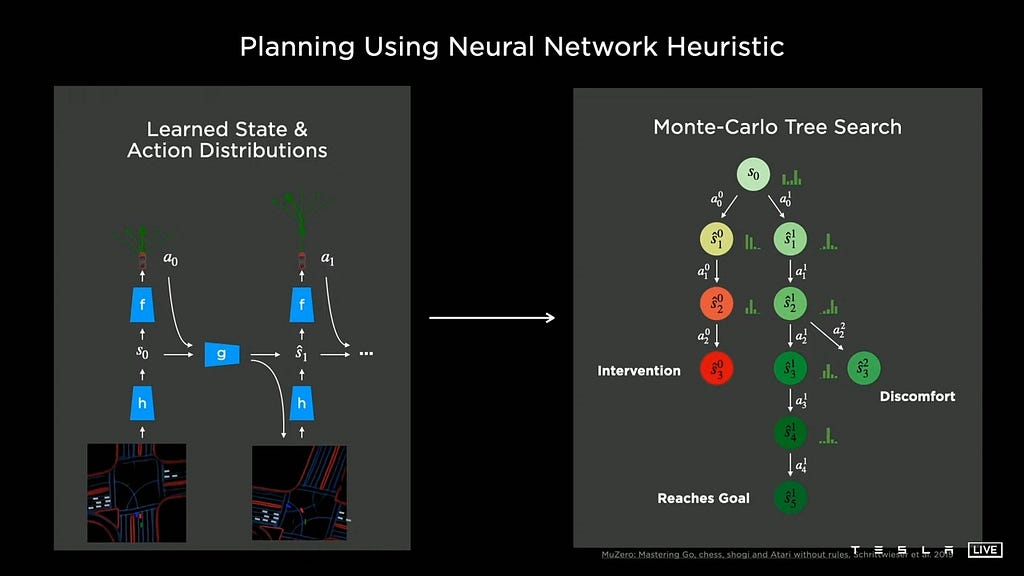
Tesla additionally adopts a hybrid system that mixes data-driven and physics-based checks. Beginning with outlined targets, Tesla’s system generates seed trajectories and evaluates key situations. It then branches out to create extra situation variants, akin to asserting or yielding to a visitors agent. Such an interplay search over the coverage tree is showcased within the shows of the years 2021 and 2022.
One spotlight of Tesla’s use of machine studying is the acceleration of tree search by way of trajectory optimization. For every node, Tesla makes use of physics-based optimization and a neural planner, attaining a ten ms vs. 100 µs time-frame — leading to a 10x to 100x enchancment. The neural community is skilled with knowledgeable demonstrations and offline optimizers.
Trajectory scoring is carried out by combining classical physics-based checks (akin to collision checks and luxury evaluation) with neural community evaluators that predict intervention probability and price human-likeness. This scoring helps prune the search house, focusing computation on probably the most promising outcomes.
Whereas many argue that machine studying ought to be utilized to high-level decision-making, Tesla makes use of ML essentially to speed up optimization and, consequently, tree search.
The Monte Carlo Tree Search (MCTS) methodology seems to be an final instrument for decision-making. Apparently, these finding out Massive Language Fashions (LLMs) are attempting to include MCTS into LLMs, whereas these engaged on autonomous driving are trying to exchange MCTS with LLMs.
As of roughly two years in the past, Tesla’s know-how adopted this method. Nonetheless, since March 2024, Tesla’s Full Self-Driving (FSD) has switched to a extra end-to-end method, considerably completely different from their earlier strategies.
No bushes
We will nonetheless think about interactions with out implicitly rising bushes. Advert-hoc logics will be applied to carry out one-order interplay between prediction and planning. Even one-order interplay can already generate good habits, as demonstrated by TuSimple. MPDM, in its authentic type, is basically one-order interplay, however executed in a extra principled and extendable method.
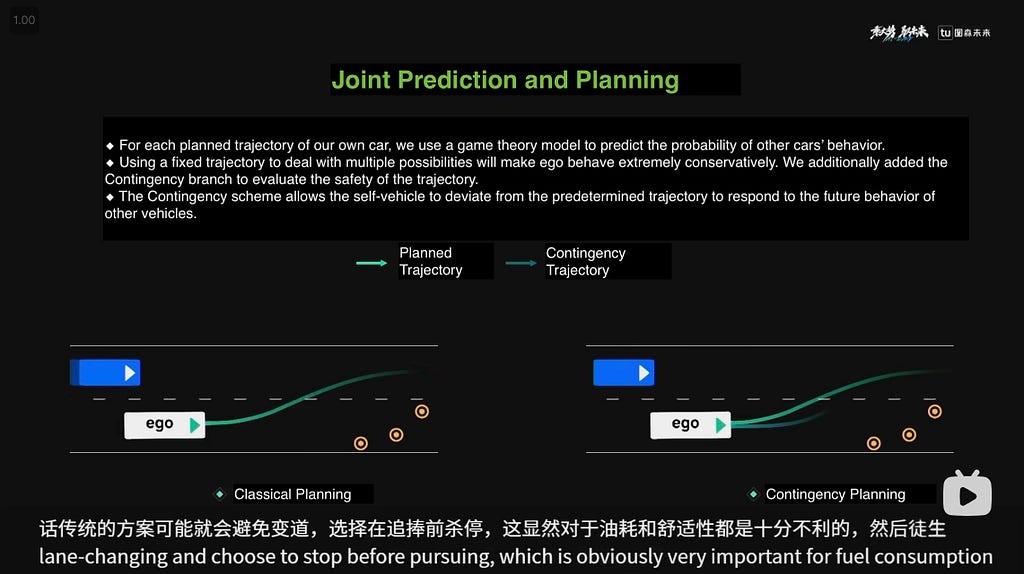
TuSimple has additionally demonstrated the aptitude to carry out contingency planning, much like the method proposed in MARC (although MARC also can accommodate a custom-made threat desire).
Self-Reflections
After studying the fundamental constructing blocks of classical planning programs, together with habits planning, movement planning, and the principled option to deal with interplay by means of decision-making, I’ve been reflecting on potential bottlenecks within the system and the way machine studying (ML) and neural networks (NN) might assist. I’m documenting my thought course of right here for future reference and for others who might have related questions. Notice that the data on this part might include private biases and speculations.
Why NN in planning?
Let’s have a look at the issue from three completely different views: within the current modular pipeline, as an end-to-end (e2e) NN planner, or as an e2e autonomous driving system.
Going again to the drafting board, let’s overview the issue formulation of a planning system in autonomous driving. The purpose is to acquire a trajectory that ensures security, consolation, and effectivity in a extremely unsure and interactive setting, all whereas adhering to real-time engineering constraints onboard the automobile. These components are summarized as targets, environments, and constraints within the chart beneath.
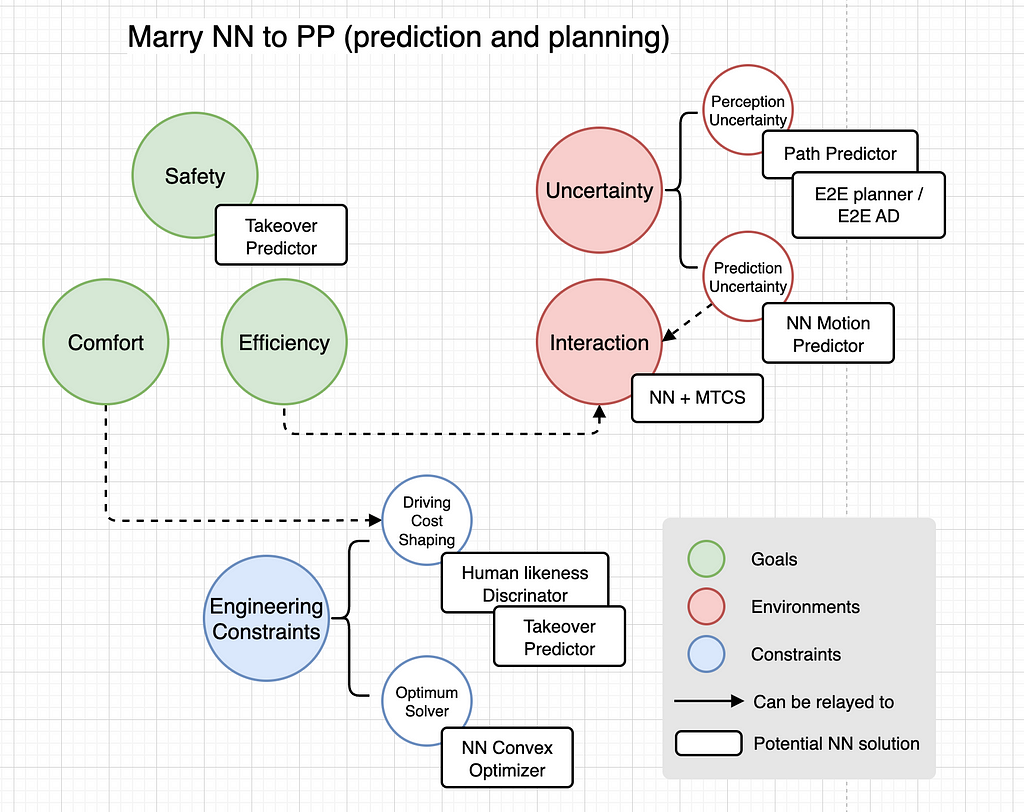
Uncertainty in autonomous driving can seek advice from uncertainty in notion (statement) and predicting long-term agent behaviors into the long run. Planning programs should additionally deal with the uncertainty in future trajectory predictions of different brokers. As mentioned earlier, a principled decision-making system is an efficient option to handle this.
Moreover, a usually neglected facet is that planning should tolerate unsure, imperfect, and typically incomplete notion outcomes, particularly within the present age of vision-centric and HD map-less driving. Having a Customary Definition (SD) map onboard as a previous helps alleviate this uncertainty, nevertheless it nonetheless poses important challenges to a closely handcrafted planner system. This notion uncertainty was thought-about a solved drawback by Stage 4 (L4) autonomous driving firms by means of the heavy use of Lidar and HD maps. Nonetheless, it has resurfaced because the business strikes towards mass manufacturing autonomous driving options with out these two crutches. An NN planner is extra sturdy and might deal with largely imperfect and incomplete notion outcomes, which is vital to mass manufacturing vision-centric and HD-mapless Superior Driver Help Programs (ADAS).
Interplay ought to be handled with a principled decision-making system akin to Monte Carlo Tree Search (MCTS) or a simplified model of MPDM. The primary problem is coping with the curse of dimensionality (combinatorial explosion) by rising a balanced coverage tree with good pruning by means of area data of autonomous driving. MPDM and its variants, in each academia and business (e.g., Tesla), present good examples of tips on how to develop this tree in a balanced method.
NNs also can improve the real-time efficiency of planners by rushing up movement planning optimization. This may shift the compute load from CPU to GPU, attaining orders of magnitude speedup. A tenfold improve in optimization pace can essentially impression high-level algorithm design, akin to MCTS.
Trajectories additionally have to be extra human-like. Human likeness and takeover predictors will be skilled with the huge quantity of human driving information obtainable. It’s extra scalable to extend the compute pool moderately than preserve a rising military of engineering abilities.
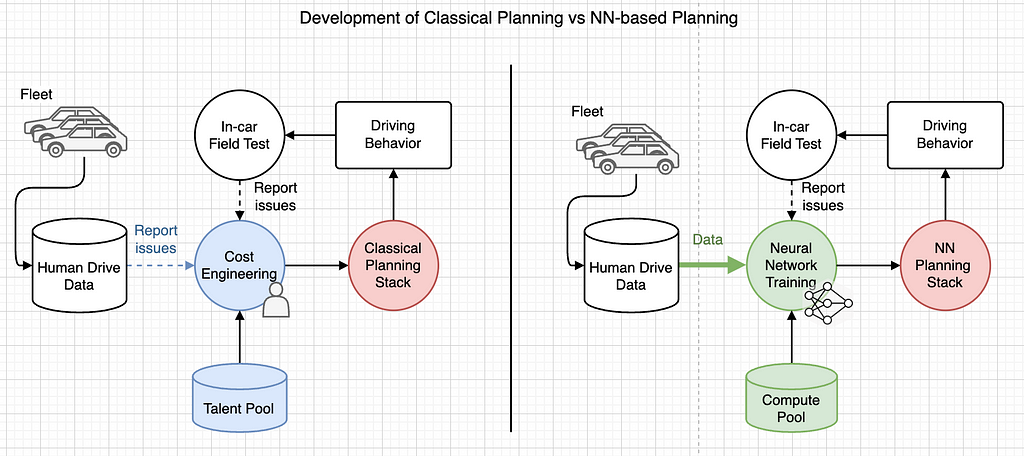
What about e2e NN planners?
An end-to-end (e2e) neural community (NN) planner nonetheless constitutes a modular autonomous driving (AD) design, accepting structured notion outcomes (and doubtlessly latent options) as its enter. This method combines prediction, resolution, and planning right into a single community. Corporations akin to DeepRoute (2022) and Huawei (2024) declare to make the most of this methodology. Notice that related uncooked sensor inputs, akin to navigation and ego automobile info, are omitted right here.
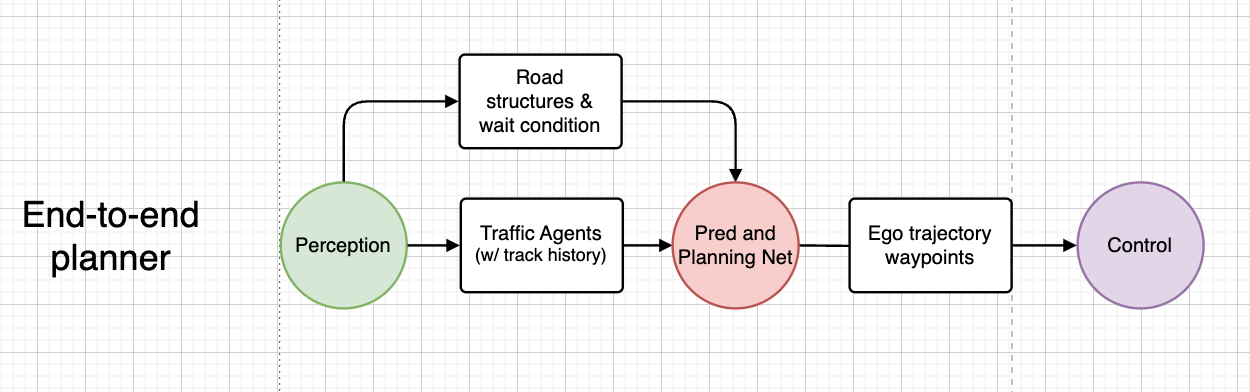
This e2e planner will be additional developed into an end-to-end autonomous driving system that mixes each notion and planning. That is what Wayve’s LINGO-2 (2024) and Tesla’s FSDv12 (2024) declare to obtain.
The advantages of this method are twofold. First, it addresses notion points. There are a lot of points of driving that we can’t simply mannequin explicitly with generally used notion interfaces. For instance, it’s fairly difficult to handcraft a driving system to nudge round a puddle of water or decelerate for dips or potholes. Whereas passing intermediate notion options may assist, it might not essentially resolve the subject.
Moreover, emergent habits will probably assist resolve nook instances extra systematically. The clever dealing with of edge instances, such because the examples above, might outcome from the emergent habits of enormous fashions.
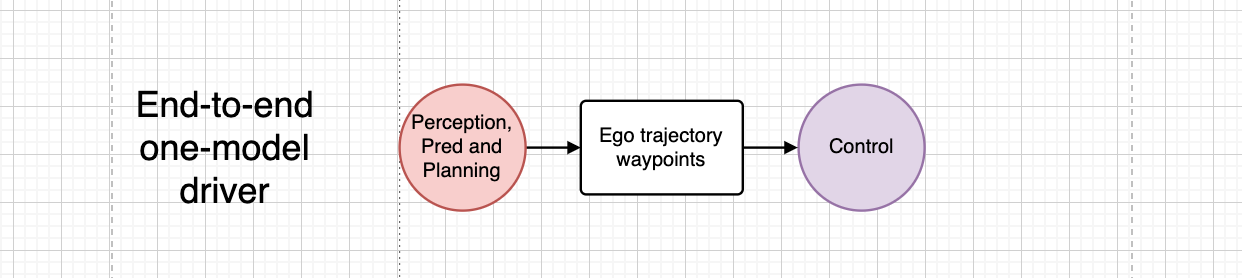
My hypothesis is that, in its final type, the end-to-end (e2e) driver can be a big imaginative and prescient and action-native multimodal mannequin enhanced by Monte Carlo Tree Search (MCTS), assuming no computational constraints.
A world mannequin in autonomous driving, as of 2024 consensus, is usually a multimodal mannequin overlaying a minimum of imaginative and prescient and motion modes (or a VA mannequin). Whereas language will be helpful for accelerating coaching, including controllability, and offering explainability, it’s not important. In its totally developed type, a world mannequin can be a VLA (vision-language-action) mannequin.
There are a minimum of two approaches to creating a world mannequin:
- Video-Native Mannequin: Prepare a mannequin to foretell future video frames, conditioned on or outputting accompanying actions, as demonstrated by fashions like GAIA-1.
- Multimodality Adaptors: Begin with a pretrained Massive Language Mannequin (LLM) and add multimodality adaptors, as seen in fashions like Lingo-2, RT2, or ApolloFM. These multimodal LLMs usually are not native to imaginative and prescient or motion however require considerably much less coaching sources.
A world mannequin can produce a coverage itself by means of the motion output, permitting it to drive the automobile straight. Alternatively, MCTS can question the world mannequin and use its coverage outputs to information the search. This World Mannequin-MCTS method, whereas rather more computationally intensive, may have the next ceiling in dealing with nook instances because of its express reasoning logic.
Can we do with out prediction?
Most present movement prediction modules symbolize the long run trajectories of brokers aside from the ego automobile as one or a number of discrete trajectories. It stays a query whether or not this prediction-planning interface is ample or mandatory.
In a classical modular pipeline, prediction continues to be wanted. Nonetheless, a predict-then-plan pipeline positively caps the higher restrict of autonomous driving programs, as mentioned within the decision-making session. A extra vital query is tips on how to combine this prediction module extra successfully into the general autonomous driving stack. Prediction ought to assist decision-making, and a queryable prediction module inside an general decision-making framework, akin to MPDM and its variants, is most popular. There are not any extreme points with concrete trajectory predictions so long as they’re built-in appropriately, akin to by means of coverage tree rollouts.
One other subject with prediction is that open-loop Key Efficiency Indicators (KPIs), akin to Common Displacement Error (ADE) and Last Displacement Error (FDE), usually are not efficient metrics as they fail to replicate the impression on planning. As a substitute, metrics like recall and precision on the intent degree ought to be thought-about.
In an end-to-end system, an express prediction module might not be mandatory, however implicit supervision — together with different area data from a classical stack — can positively assist or a minimum of enhance the information effectivity of the training system. Evaluating the prediction habits, whether or not express or implicit, will even be useful in debugging such an e2e system.
Can we do with simply nets however no bushes?
Conclusions First. For an assistant, neural networks (nets) can obtain very excessive, even superhuman efficiency. For brokers, I imagine that utilizing a tree construction continues to be helpful (although not essentially a should).
To begin with, bushes can enhance nets. Bushes improve the efficiency of a given community, whether or not it’s NN-based or not. In AlphaGo, even with a coverage community skilled by way of supervised studying and reinforcement studying, the general efficiency was nonetheless inferior to the MCTS-based AlphaGo, which integrates the coverage community as one element.
Second, nets can distill bushes. In AlphaGo, MCTS used each a worth community and the reward from a quick rollout coverage community to guage a node (state or board place) within the tree. The AlphaGo paper additionally talked about that whereas a worth perform alone could possibly be used, combining the outcomes of the 2 yielded the most effective outcomes. The worth community primarily distilled the data from the coverage rollout by straight studying the state-value pair. That is akin to how people distill the logical pondering of the gradual System 2 into the quick, intuitive responses of System 1. Daniel Kahneman, in his e book “Considering, Quick and Gradual,” describes how a chess grasp can rapidly acknowledge patterns and make fast choices after years of observe, whereas a novice would require important effort to realize related outcomes. Equally, the worth community in AlphaGo was skilled to offer a quick analysis of a given board place.
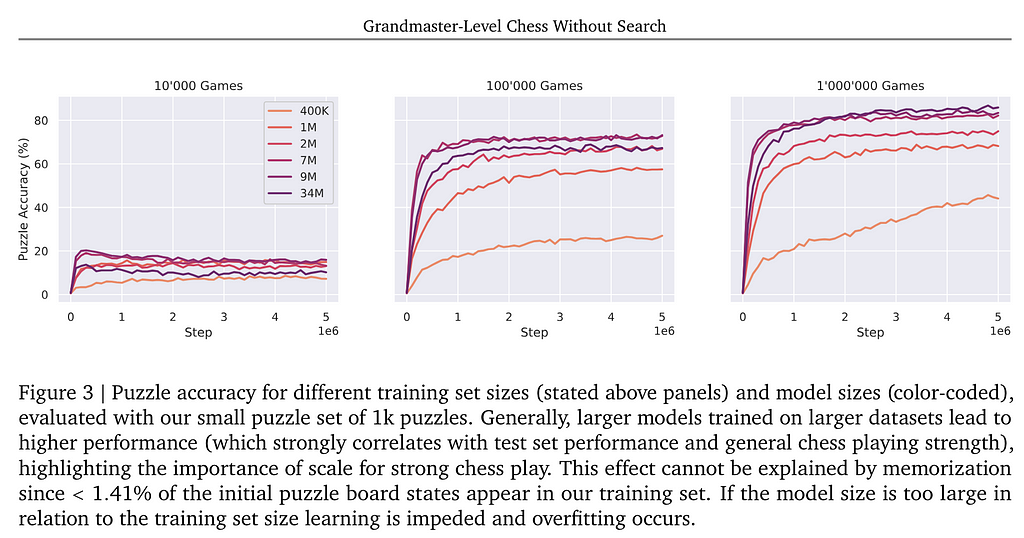
Current papers discover the higher limits of this quick system with neural networks. The “chess with out search” paper demonstrates that with ample information (ready by means of tree search utilizing a standard algorithm), it’s attainable to realize grandmaster-level proficiency. There’s a clear “scaling regulation” associated to information measurement and mannequin measurement, indicating that as the quantity of information and the complexity of the mannequin improve, so does the proficiency of the system.
So right here we’re with an influence duo: bushes enhance nets, and nets distill bushes. This optimistic suggestions loop is basically what AlphaZero makes use of to bootstrap itself to achieve superhuman efficiency in a number of video games.
The identical rules apply to the event of enormous language fashions (LLMs). For video games, since we have now clearly outlined rewards as wins or losses, we are able to use ahead rollout to find out the worth of a sure motion or state. For LLMs, the rewards usually are not as clear-cut as within the recreation of Go, so we depend on human preferences to price the fashions by way of reinforcement studying with human suggestions (RLHF). Nonetheless, with fashions like ChatGPT already skilled, we are able to use supervised fine-tuning (SFT), which is basically imitation studying, to distill smaller but nonetheless highly effective fashions with out RLHF.
Returning to the unique query, nets can obtain extraordinarily excessive efficiency with massive portions of high-quality information. This could possibly be ok for an assistant, relying on the tolerance for errors, nevertheless it might not be ample for an autonomous agent. For programs focusing on driving help (ADAS), nets by way of imitation studying could also be ample.
Bushes can considerably enhance the efficiency of nets with an express reasoning loop, making them maybe extra appropriate for totally autonomous brokers. The extent of the tree or reasoning loop relies on the return on funding of engineering sources. For instance, even one order of interplay can present substantial advantages, as demonstrated in TuSimple AI Day.
Can we use LLMs to make choices?
From the abstract beneath of the most well liked representatives of AI programs, we are able to see that LLMs usually are not designed to carry out decision-making. In essence, LLMs are skilled to finish paperwork, and even SFT-aligned LLM assistants deal with dialogues as a particular kind of doc (finishing a dialogue file).
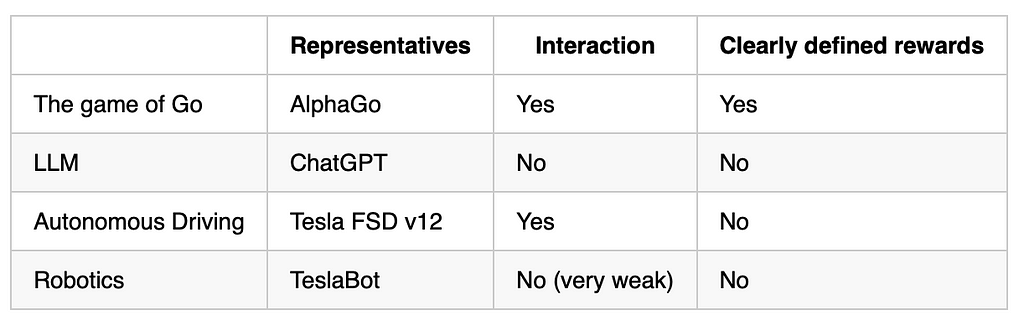
I don’t totally agree with latest claims that LLMs are gradual programs (System 2). They’re unnecessarily gradual in inference because of {hardware} constraints, however of their vanilla type, LLMs are quick programs as they can’t carry out counterfactual checks. Prompting methods akin to Chain of Thought (CoT) or Tree of Ideas (ToT) are literally simplified types of MCTS, making LLMs perform extra like slower programs.
There may be intensive analysis attempting to combine full-blown MCTS with LLMs. Particularly, LLM-MCTS (NeurIPS 2023) treats the LLM as a commonsense “world mannequin” and makes use of LLM-induced coverage actions as a heuristic to information the search. LLM-MCTS outperforms each MCTS alone and insurance policies induced by LLMs by a large margin for complicated, novel duties. The extremely speculated Q-star from OpenAI appears to comply with the identical method of boosting LLMs with MCTS, because the title suggests.
The pattern of evolution
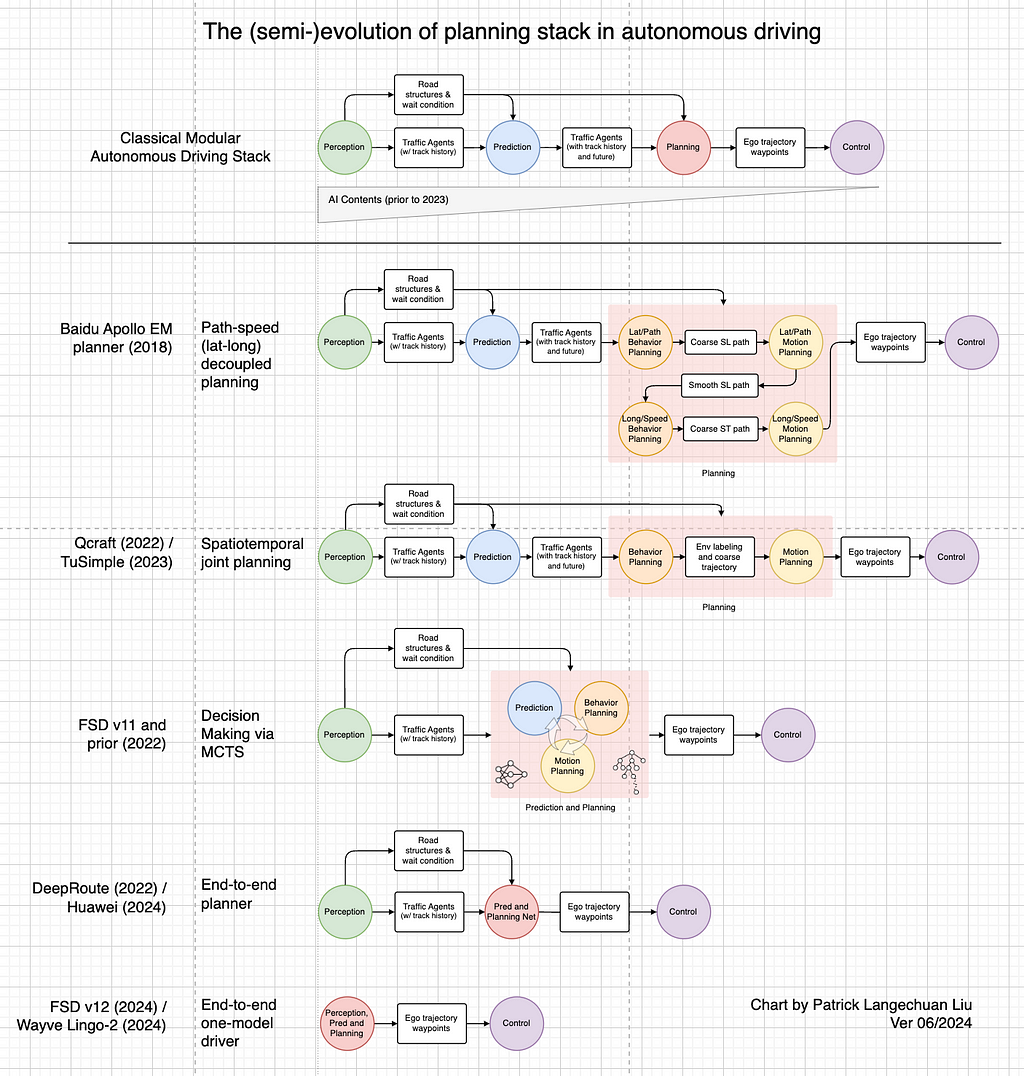
Beneath is a tough evolution of the planning stack in autonomous driving. It’s tough because the listed options usually are not essentially extra superior than those above, and their debut might not comply with the precise chronological order. Nonetheless, we are able to observe normal traits. Notice that the listed consultant options from the business are primarily based on my interpretation of varied press releases and could possibly be topic to error.
One pattern is the motion in the direction of a extra end-to-end design with extra modules consolidated into one. We see the stack evolve from path-speed decoupled planning to joint spatiotemporal planning, and from a predict-then-plan system to a joint prediction and planning system. One other pattern is the rising incorporation of machine learning-based elements, particularly within the final three phases. These two traits converge in the direction of an end-to-end NN planner (with out notion) and even an end-to-end NN driver (with notion).
Takeaways
- ML as a Software: Machine studying is a instrument, not a standalone answer. It could possibly help with planning even in present modular designs.
- Full Formulation: Begin with a full drawback formulation, then make cheap assumptions to steadiness efficiency and sources. This helps create a transparent route for a future-proof system design and permits for enhancements as sources improve. Recall the transition from POMDP’s formulation to engineering options like AlphaGo’s MCTS and MPDM.
- Adapting Algorithms: Theoretically stunning algorithms (e.g., Dijkstra and Worth Iteration) are nice for understanding ideas however want adaptation for sensible engineering (Worth Iteration to MCTS as Dijkstra’s algorithm to Hybrid A-star).
- Deterministic vs. Stochastic: Planning excels in resolving deterministic (not essentially static) scenes. Choice-making in stochastic scenes is probably the most difficult activity towards full autonomy.
- Contingency Planning: This will help merge a number of futures into a standard motion. It’s helpful to be aggressive to the diploma you could all the time resort to a backup plan.
- Finish-to-end Fashions: Whether or not an end-to-end mannequin can resolve full autonomy stays unclear. It might nonetheless want classical strategies like MCTS. Neural networks can deal with assistants, whereas bushes can handle brokers.
Acknowledgments
- This weblog put up is closely impressed by Dr. Wenchao Ding’s course on planning on Shenlan Xueyuan (深蓝学院).
- Thanks for the heavy and provoking dialogue with Naiyan Wang and Jingwei Zhao. Due to 论文推土机, Invictus, XXF and PYZ for giving vital suggestions to the preliminary draft. Thanks for the insightful dialogue with Professor Wei Zhan from Berkeley on traits in academia.
Reference
- Finish-To-Finish Planning of Autonomous Driving in Business and Academia: 2022–2023, Arxiv 2024
- BEVGPT: Generative Pre-trained Massive Mannequin for Autonomous Driving Prediction, Choice-Making, and Planning, AAAI 2024
- In the direction of A Common-Goal Movement Planning for Autonomous Automobiles Utilizing Fluid Dynamics
- Tusimple AI day, in Chinese language with English subtitle on Bilibili, 2023/07
- Tech weblog on joint spatiotemporal planning by Qcraft, in Chinese language on Zhihu, 2022/08
- A overview of your complete autonomous driving stack, in Chinese language on Zhihu, 2018/12
- Tesla AI Day Planning, in Chinese language on Zhihu, 2022/10
- Technical weblog on ApolloFM, in Chinese language by Tsinghua AIR, 2024
- Optimum Trajectory Technology for Dynamic Avenue Eventualities in a Frenet Body, ICRA 2010
- MP3: A Unified Mannequin to Map, Understand, Predict and Plan, CVPR 2021
- NMP: Finish-to-end Interpretable Neural Movement Planner, CVPR 2019 oral
- Elevate, Splat, Shoot: Encoding Photographs From Arbitrary Digital camera Rigs by Implicitly Unprojecting to 3D, ECCV 2020
- CoverNet: Multimodal Habits Prediction utilizing Trajectory Units, CVPR 2020
- Baidu Apollo EM Movement Planner, Baidu, 2018
- AlphaGo: Mastering the sport of Go together with deep neural networks and tree search, Nature 2016
- AlphaZero: A normal reinforcement studying algorithm that masters chess, shogi, and Undergo self-play, Science 2017
- MuZero: Mastering Atari, Go, chess and shogi by planning with a discovered mannequin, Nature 2020
- ToT: Tree of Ideas: Deliberate Drawback Fixing with Massive Language Fashions, NeurIPS 2023 Oral
- CoT: Chain-of-Thought Prompting Elicits Reasoning in Massive Language Fashions, NeurIPS 2022
- LLM-MCTS: Massive Language Fashions as Commonsense Data for Massive-Scale Activity Planning, NeurIPS 2023
- MPDM: Multipolicy decision-making in dynamic, unsure environments for autonomous driving, ICRA 2015
- MPDM2: Multipolicy Choice-Making for Autonomous Driving by way of Changepoint-based Habits Prediction, RSS 2015
- MPDM3: Multipolicy decision-making for autonomous driving by way of changepoint-based habits prediction: Idea and experiment, RSS 2017
- EUDM: Environment friendly Uncertainty-aware Choice-making for Automated Driving Utilizing Guided Branching, ICRA 2020
- MARC: Multipolicy and Threat-aware Contingency Planning for Autonomous Driving, RAL 2023
- EPSILON: An Environment friendly Planning System for Automated Automobiles in Extremely Interactive Environments, TRO 2021
A Crash Course of Planning for Notion Engineers in Autonomous Driving was initially revealed in In the direction of Knowledge Science on Medium, the place persons are persevering with the dialog by highlighting and responding to this story.