


































")




{kind=link}

Unlock hidden patterns in your information with the chi-squared check in Python.
Half 1: What’s Chi-Squared Take a look at?
When discussing speculation testing, there are numerous approaches we will take, relying on the actual circumstances. Frequent exams just like the z-test and t-test are the go-to strategies to check our hypotheses (null and various hypotheses). The metric we need to check differs relying on the issue. Normally, in producing hypotheses, we contain inhabitants imply or inhabitants proportion because the metric to state them. Let’s say we need to check whether or not the inhabitants proportion of the scholars who took the mathematics check who acquired 75 is greater than 80%. Let the null speculation be denoted by H0, and the choice speculation be denoted by H1; we generate the hypotheses by:

After that, we must always see our information, whether or not the inhabitants variance is understood or unknown, to resolve which check statistic method we must always use. On this case, we use z-statistic for proportion method. To calculate the check statistics from our pattern, first, we estimate the inhabitants proportion by dividing the full variety of college students who acquired 75 by the full variety of college students who participated within the check. After that, we plug within the estimated proportion to calculate the check statistic utilizing the check statistic method. Then, we decide from the check statistic outcome if it’s going to reject or fail to reject the null speculation by evaluating it with the rejection area or p-value.
However what if we need to check totally different circumstances? What if we make inferences concerning the proportion of the group of scholars (e.g., class A, B, C, and so on.) variable in our dataset? What if we need to check if there may be any affiliation between teams of scholars and their preparation earlier than the examination (are they doing additional programs exterior college or not)? Is it impartial or not? What if we need to check categorical information and infer their inhabitants in our dataset? To check that, we’ll be utilizing the chi-squared check.
The chi-squared check is crafted to assist us draw conclusions about categorical information that fall into totally different classes. It compares every class’s noticed frequencies (counts) to the anticipated frequencies underneath the null speculation. Denoted as X², chi-squared has a distribution, specifically chi-squared distribution, permitting us to find out the importance of the noticed deviations from anticipated values.
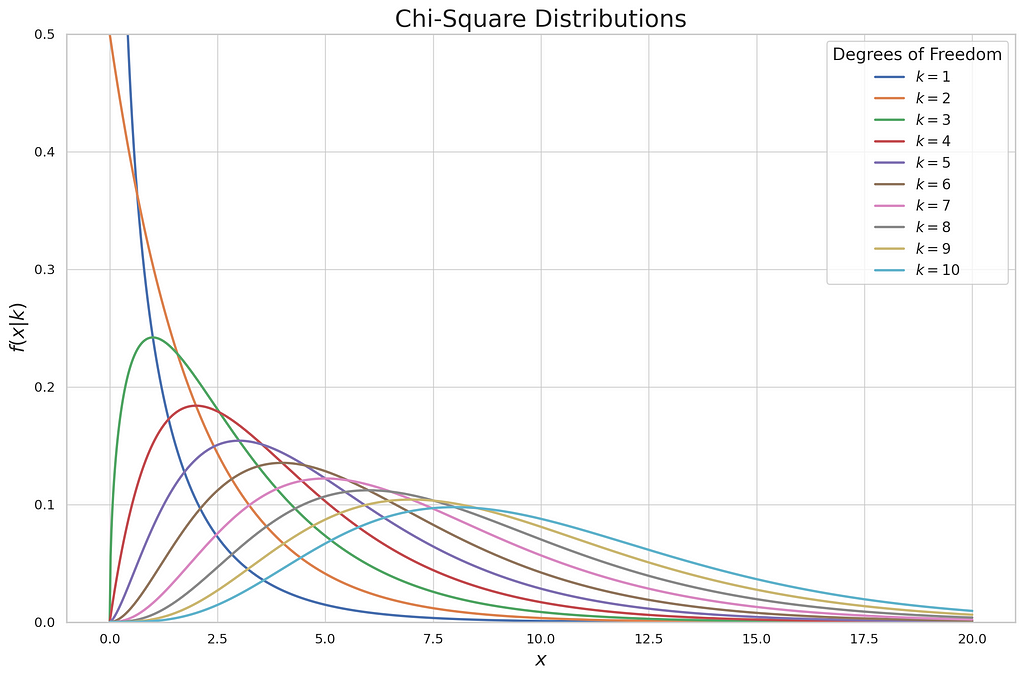
The plot describes the continual distribution of every diploma of freedom within the chi-squared check. Within the chi-squared check, to show whether or not we are going to reject or fail to reject the null speculation, we don’t use the z or t desk to resolve, however we use the chi-squared desk. It lists possibilities of chosen significance stage and diploma of freedom of chi-squared. There are two varieties of chi-squared exams, the chi-squared goodness-of-fit check and the chi-squared check of a contingency desk. Every of those sorts has a unique function when tackling the speculation check. In parallel with the theoretical method of every check, I’ll present you tips on how to exhibit these two exams in sensible examples.
Half 2: Chi-squared goodness-of-fit check
That is the primary kind of the chi-squared check. This check analyzes a gaggle of categorical information from a single categorical variable with ok classes. It’s used to particularly clarify the proportion of observations in every class throughout the inhabitants. For instance, we surveyed 1000 college students who acquired no less than 75 on their math check. We noticed that from 5 teams of scholars (Class A to E), the distribution is like this:
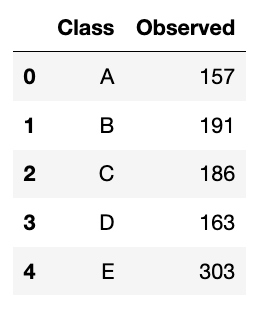
We’ll do it in each guide and Python methods. Let’s begin with the guide one.
Type Hypotheses
As we all know, we now have already surveyed 1000 college students. I need to check whether or not the inhabitants proportions in every class are equal. The hypotheses will be:
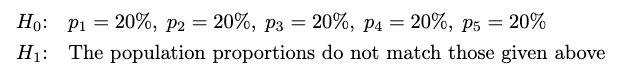
Take a look at Statistic
The check statistic method for the chi-squared goodness-of-fit check is like this:

The place:
- ok: variety of classes
- fi: noticed counts
- ei: anticipated counts
We have already got the variety of classes (5 from Class A to E) and the noticed counts, however we don’t have the anticipated counts but. To calculate that, we must always mirror on our hypotheses. On this case, I assume that every one class proportions are the identical, which is 20%. We’ll make one other column within the dataset named Anticipated. We calculate it by multiplying the full variety of observations by the proportion we select:
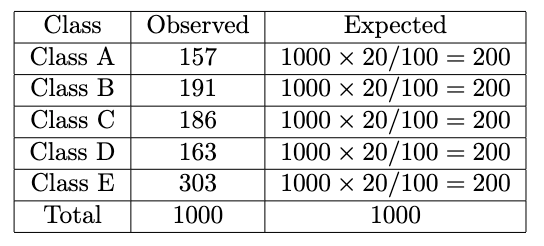
Now we plug within the method like this for every noticed and anticipated worth:
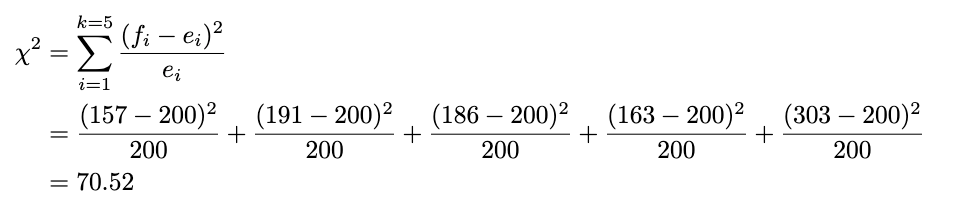
We have already got the check statistic outcome. However how can we resolve whether or not it’s going to reject or fail to reject the null speculation?
Resolution Rule
As talked about above, we’ll use the chi-squared desk to match the check statistic. Keep in mind that a small check statistic helps the null speculation, whereas a big check statistic helps the choice speculation. So, we must always reject the null speculation when the check statistic is substantial (which means that is an upper-tailed check). As a result of we do that manually, we use the rejection area to resolve whether or not it’s going to reject or fail to reject the null speculation. The rejection area is outlined as under:
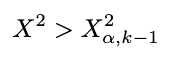
The place:
- α: Significance Degree
- ok: variety of classes
The rule of thumb is: If our check statistic is extra important than the chi-squared desk worth we glance up, we reject the null speculation. We’ll use the importance stage of 5% and take a look at the chi-squared desk. The worth of chi-squared with a 5% significance stage and levels of freedom of 4 (5 classes minus 1), we get 9.49. As a result of our check statistic is far more important than the chi-squared desk worth (70.52 > 9.49), we reject the null speculation at a 5% significance stage. Now, you already know tips on how to carry out the chi-squared goodness-of-fit check!
Python Method
That is the Python method to the chi-squared goodness-of-fit check utilizing SciPy:
import pandas as pd
from scipy.stats import chisquare
# Outline the scholar information
information = {
'Class': ['A', 'B', 'C', 'D', 'E'],
'Noticed': [157, 191, 186, 163, 303]
}
# Remodel dictionary into dataframe
df = pd.DataFrame(information)
# Outline the null and various hypotheses
null_hypothesis = "p1 = 20%, p2 = 20%, p3 = 20%, p4 = 20%, p5 = 20%"
alternative_hypothesis = "The inhabitants proportions don't match the given proportions"
# Calculate the full variety of observations and the anticipated depend for every class
total_count = df['Observed'].sum()
expected_count = total_count / len(df) # As there are 5 classes
# Create an inventory of noticed and anticipated counts
observed_list = df['Observed'].tolist()
expected_list = [expected_count] * len(df)
# Carry out the Chi-Squared goodness-of-fit check
chi2_stat, p_val = chisquare(f_obs=observed_list, f_exp=expected_list)
# Print the outcomes
print(f"nChi2 Statistic: {chi2_stat:.2f}")
print(f"P-value: {p_val:.4f}")
# Print the conclusion
if p_val < 0.05:
print("Reject the null speculation: The inhabitants proportions don't match the given proportions.")
else:
print("Fail to reject the null speculation: The inhabitants proportions match the given proportions.")
Utilizing the p-value, we additionally acquired the identical outcome. We reject the null speculation at a 5% significance stage.

Half 3: Chi-squared check of a contingency desk
We already know tips on how to make inferences concerning the proportion of 1 categorical variable. However what if I need to check whether or not two categorical variables are impartial?
To check that, we use the chi-squared check of the contingency desk. We’ll make the most of the contingency desk to calculate the check statistic worth. A contingency desk is a cross-tabulation desk that classifies counts summarizing the mixed distribution of two categorical variables, every having a finite variety of classes. From this desk, you can decide if the distribution of 1 categorical variable is constant throughout all classes of the opposite categorical variable.
I’ll clarify tips on how to do it manually and utilizing Python. On this instance, we sampled 1000 college students who acquired no less than 75 on their math check. I need to check whether or not the variable of a gaggle of scholars and the variable of the scholars who’ve taken the supplementary course (Taken or Not) exterior the varsity earlier than the check is impartial. The distribution is like this:

Type Hypotheses
To generate these hypotheses may be very easy. We outline the hypotheses as:
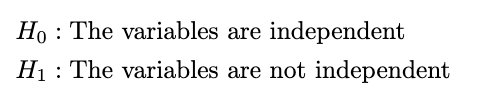
Take a look at Statistic
That is the toughest half. In dealing with actual information, I counsel you employ Python or different statistical software program immediately as a result of the calculation is just too sophisticated if we do it manually. However as a result of we need to know the method from the method, let’s do the guide calculation. The check statistic of this check is:
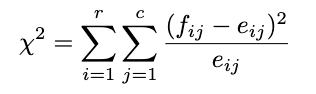
The place:
- r = variety of rows
- c = variety of columns
- fij: the noticed counts
- eij = (i th row complete * j th row complete)/pattern measurement
Recall Determine 9, these values are simply noticed ones. Earlier than we use the check statistic method, we must always calculate the anticipated counts. We try this by:
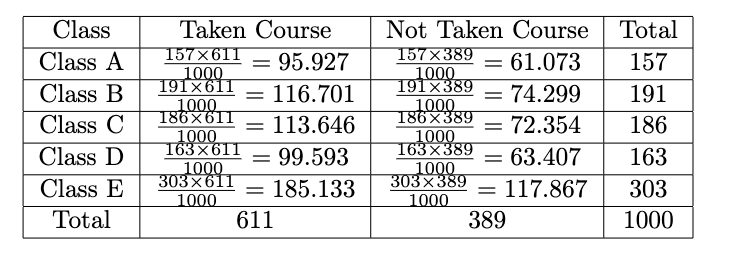
Now we get the noticed and anticipated counts. After that, we are going to calculate the check statistic by:
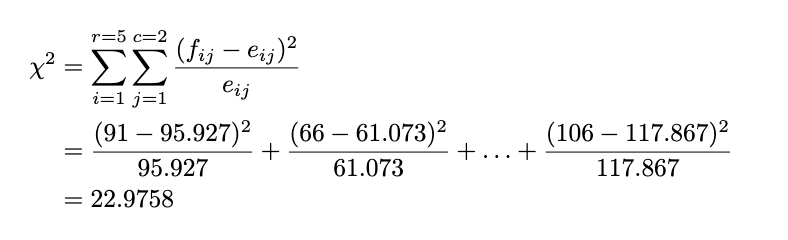
Resolution Rule
We have already got the check statistic; now we evaluate it with the rejection area. The rejection area for the contingency desk check is outlined by:

The place:
- α: Significance Degree
- r = variety of rows
- c = variety of columns
The rule of thumb is identical because the goodness-of-fit check: If our check statistic is extra important than the chi-squared desk worth we glance up, we reject the null speculation. We’ll use the importance stage of 5%. As a result of the full row is 5 and the full column is 2, we glance up the worth of chi-squared with a 5% significance stage and levels of freedom of (5–1) * (2–1) = 4, and we get 15.5. As a result of the check statistic is decrease than the chi-squared desk worth (22.9758 > 15.5), we reject the null speculation at a 5% significance stage.
Python Method
That is the Python method to the chi-squared contingency desk check utilizing SciPy:
import pandas as pd
from scipy.stats import chi2_contingency
# Create the dataset
information = {
'Class': ['group A', 'group B', 'group C', 'group D', 'group E'],
'Taken Course': [91, 131, 117, 75, 197],
'Not Taken Course': [66, 60, 69, 88, 106]
}
# Create a DataFrame
df = pd.DataFrame(information)
df.set_index('Class', inplace=True)
# Carry out the Chi-Squared check for independence
chi2_stat, p_val, dof, anticipated = chi2_contingency(df)
# Print the outcomes
print("Anticipated Counts:")
print(pd.DataFrame(anticipated, index=df.index, columns=df.columns))
print(f"nChi2 Statistic: {chi2_stat:.4f}")
print(f"P-value: {p_val:.4f}")
# Print the conclusion
if p_val < 0.05:
print("nReject the null speculation: The variables are usually not impartial")
else:
print("nFail to reject the null speculation: The variables are impartial")
Utilizing the p-value, we additionally acquired the identical outcome. We reject the null speculation at a 5% significance stage.
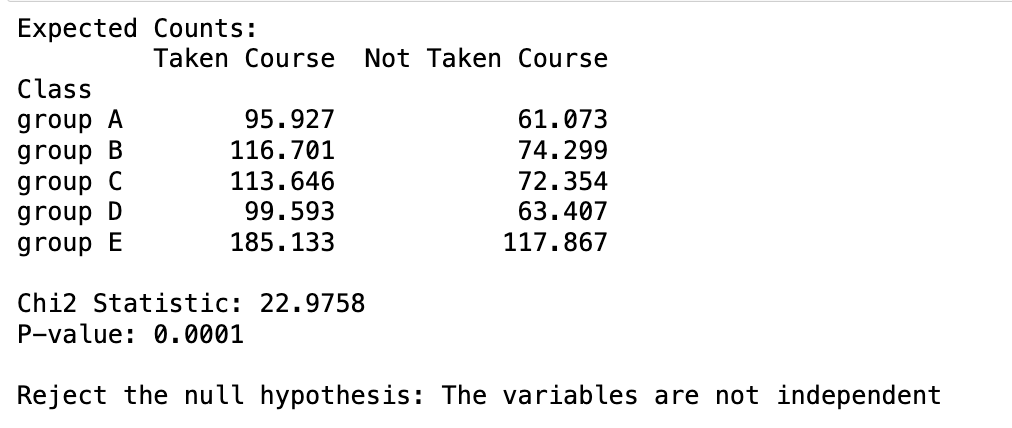
Now that you just perceive tips on how to conduct speculation exams utilizing the chi-square check technique, it’s time to use this data to your individual information. Completely satisfied experimenting!
Half 4: Conclusion
The chi-squared check is a robust statistical technique that helps us perceive the relationships and distributions inside categorical information. Forming the issue and correct hypotheses earlier than leaping into the check itself is essential. A big pattern can also be very important in conducting a chi-squared check; as an illustration, it really works effectively for sizes down to five,000 (Bergh, 2015), as small pattern sizes can result in inaccurate outcomes. To interpret outcomes accurately, select the appropriate significance stage and evaluate the chi-square statistic to the important worth from the chi-square distribution desk or the p-value.
Reference
- G. Keller, Statistics for Administration and Economics, eleventh ed., Chapter 15, Cengage Studying (2017).
- Daniel, Bergh. (2015). Chi-Squared Take a look at of Match and Pattern Dimension-A Comparability between a Random Pattern Method and a Chi-Sq. Worth Adjustment Technique.. Journal of utilized measurement, 16(2):204–217.
Chi-Squared Take a look at: Revealing Hidden Patterns in Your Knowledge was initially revealed in In the direction of Knowledge Science on Medium, the place individuals are persevering with the dialog by highlighting and responding to this story.