













 Pre-Put in Home windows 10 & MS Workplace (Path Model) and Antivirus (Free Model) (500GB)")

")
 AL15G-52, 39.62cm (15.6 inch) FHD Show, Premium Steel Physique, Metal Grey, 1.99KG")

 | 5000mAh Battery| 6.52″ HD+ Show | 13MP Twin Rear Digital camera| Entrance Flash| Trendy Design")
 5G (Blue, 8GB RAM, 128GB Storage)")
|16GB Expandable RAM | Extremely Clear 50MP Superior Rear Digicam| Dimensity 6020 7nm Highly effective 5G Processor")
, Medium")
")











{kind=link}

A short evaluate of the picture basis mannequin pre-training aims
We crave giant fashions, don’t we?
The GPT collection has proved its capacity to revolutionize the NLP world, and everybody is worked up to see the identical transformation within the pc imaginative and prescient area. The preferred picture basis fashions in recent times embody SegmentAnything, DINOv2, and lots of others. The pure query is, what are the important thing variations between the pre-training stage of those basis fashions?
As an alternative of answering this query instantly, we are going to gently evaluate the picture basis mannequin pre-training aims utilizing Masked Picture Modeling on this weblog article. We will even talk about a paper (to be) printed in ICML’24, making use of the Autoregression Modeling to basis mannequin pre-training.
What’s mannequin pre-training in LLM?
Mannequin pre-training is a terminology used basically giant fashions (LLM, picture basis fashions) to explain the stage the place no label is given to the mannequin, however coaching the mannequin purely utilizing a self-supervised method.
Widespread pre-training strategies principally originated from LLMs. For instance, the BERT mannequin used Masked Language Modeling, which impressed Masked Picture Modeling corresponding to BEiT, MAE-ViT, and SimMM. The GPT collection used Autoregressive Language Modeling, and a not too long ago accepted ICML publication prolonged this concept to Autoregressive Picture Modeling.
So, what are Masked Language Modeling and Autoregressive Language Modeling?
The Masked Language Modeling was first proposed within the BERT paper in 2018. The strategy was described as “merely masking some proportion of the enter tokens randomly after which predicting these masked tokens.” It’s a bi-directional illustration strategy, because the mannequin will attempt to predict forwards and backwards on the masked token.
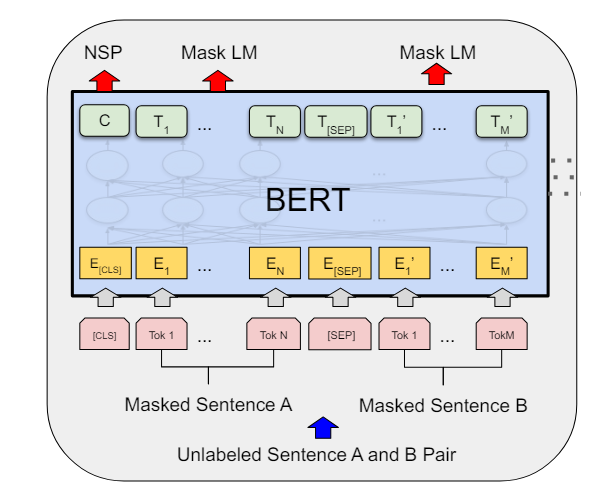
The Autoregressive Language Modeling was famously recognized from the GPT3 paper. It has a clearer definition within the XLNet paper as follows, and we are able to see the mannequin is unidirectional. The explanation the GPT collection makes use of a unidirectional language mannequin is that the structure is decoder-based, which solely wants self-attention on the immediate and the completion:

Pre-training in Picture Area
When transferring into the picture area, the quick query is how we type the picture “token sequence.” The pure considering is simply to make use of the ViT structure, breaking a picture right into a grid of picture patches (visible tokens).
BEiT. Printed as an arXiv preprint in 2022, the thought of BEiT is easy. After tokenizing a picture right into a sequence of 14*14 visible tokens, 40% of the tokens are randomly masked, changed by learnable embeddings, and fed into the transformer. The pre-training goal is to maximise the log-likelihood of the proper visible tokens, and no decoder is required for this stage. The pipeline is proven within the determine under.
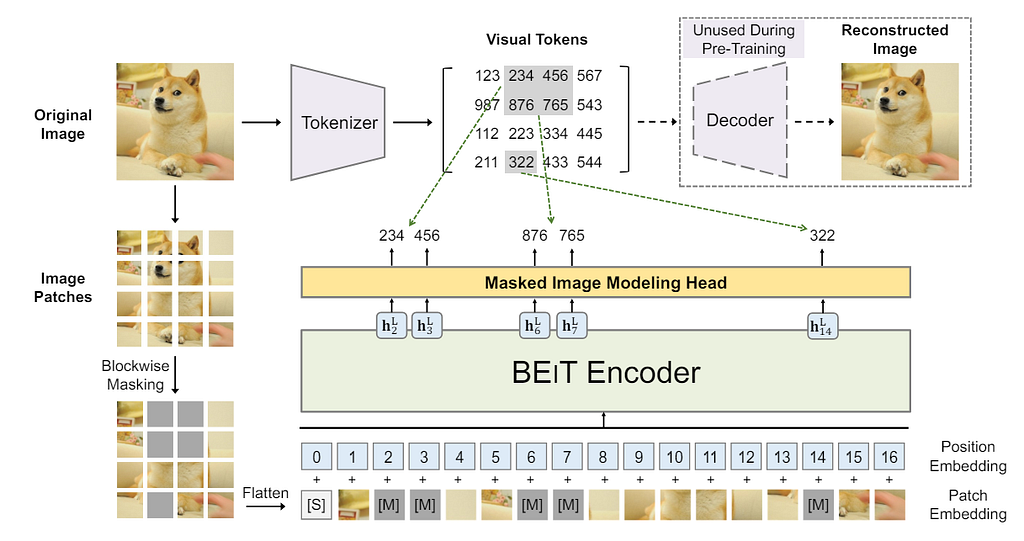
Within the authentic paper, the authors additionally supplied a theoretical hyperlink between the BEiT and the Variational Autoencoder. So the pure query is, can an Autoencoder be used for pre-training functions?
MAE-ViT. This paper answered the query above by designing a masked autoencoder structure. Utilizing the identical ViT formulation and random masking, the authors proposed to “discard” the masked patches throughout coaching and solely use unmasked patches within the visible token sequence as enter to the encoder. The masks tokens will probably be used for reconstruction throughout the decoding stage on the pre-training. The decoder could possibly be versatile, starting from 1–12 transformer blocks with dimensionality between 128 and 1024. Extra detailed architectural info could possibly be discovered within the authentic paper.

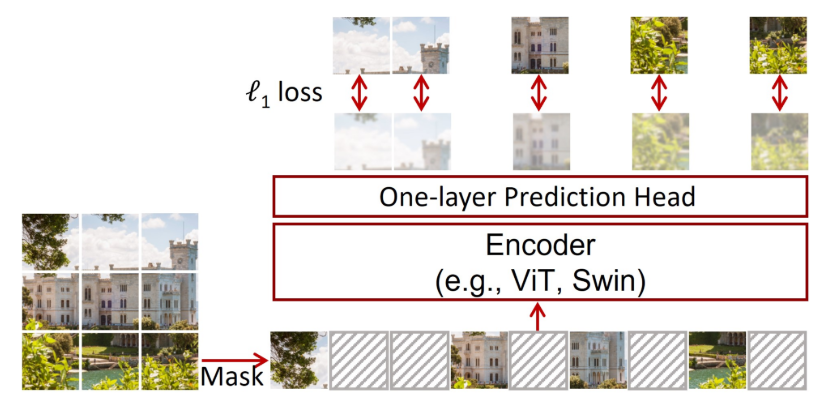
SimMIM. Barely completely different from BEiT and MAE-ViT, the paper proposes utilizing a versatile spine corresponding to Swin Transformer for encoding functions. The proposed prediction head is extraordinarily light-weight—a single linear layer of a 2-layer MLP to regress the masked pixels.
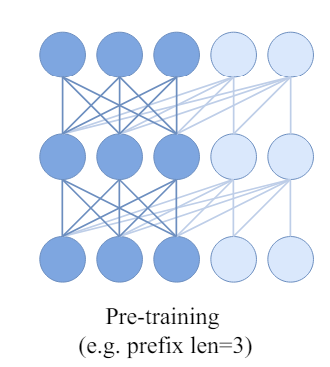
AIM. A latest paper accepted by ICML’24 proposed utilizing the Autoregressive mannequin (or causal mannequin) for pre-training functions. As an alternative of utilizing a masked sequence, the mannequin takes the total sequence to a causal transformer, utilizing prefixed self-attention with causal masks.

What’s prefixed causal consideration? There are detailed tutorials on causal consideration masking on Kaggle, and right here, it’s masking out “future” tokens on self-attention. Nevertheless, on this paper, the authors declare that the discrepancy between the causal masks and downstream bidirectional self-attention would result in a efficiency challenge. The answer is to make use of partial causal masking or prefixed causal consideration. Within the prefix sequence, bidirectional self-attention is used, and causal consideration is utilized for the remainder of the sequence.
What’s the benefit of Autoregressive Picture Masking? The reply lies within the scaling, of each the mannequin and knowledge sizes. The paper claims that the mannequin scale instantly correlates with the pre-training loss and the downstream activity efficiency (the next left subplot). The uncurated pre-training knowledge scale can be instantly linked to the downstream activity efficiency (the next proper subplot).
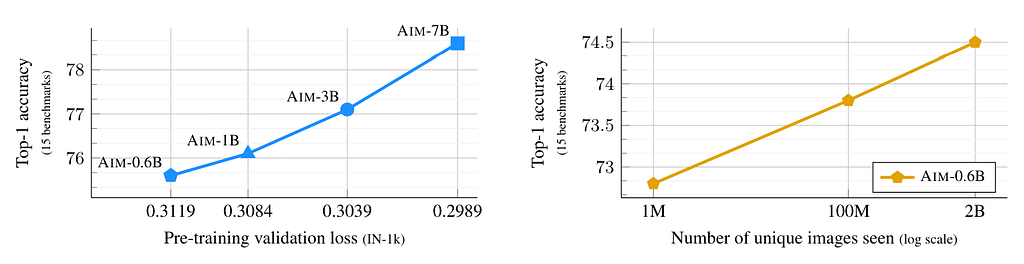
In comparison with a 50% masking ratio, the AIM achieved an astonishing 8% efficiency enhance over Masked Picture Modeling.

So, what’s the large takeaway right here? The AIM paper mentioned completely different trade-offs between the state-of-the-art pre-training strategies, and we received’t repeat them right here. A shallower however extra intuitive lesson is that there’s possible nonetheless a lot work left to enhance the imaginative and prescient basis fashions utilizing present expertise from the LLM area, particularly on scalability. Hopefully, we’ll see these enhancements within the coming years.
References
- El-Nouby et al., Scalable Pre-training of Giant Autoregressive Picture Fashions. ICML 2024. Github: https://github.com/apple/ml-aim
- Xie et al., SimMIM: a Easy Framework for Masked Picture Modeling. CVPR 2022. Github: https://github.com/microsoft/SimMIM
- Bao et al., BEiT: BERT Pre-Coaching of Picture Transformers. arXiv preprint 2022. Github: https://github.com/microsoft/unilm/tree/grasp/beit
- He et al., Masked autoencoders are scalable imaginative and prescient learners. CVPR 2022. HuggingFace Official: https://huggingface.co/docs/transformers/en/model_doc/vit_mae
- Caron et al., Rising Properties in Self-Supervised Imaginative and prescient Transformers. ICCV 2021. Github: https://github.com/facebookresearch/dino?tab=readme-ov-file
- Liu et al., Swin transformer: Hierarchical imaginative and prescient transformer utilizing shifted home windows. ICCV 2021. Github: https://github.com/microsoft/Swin-Transformer
- Brown et al., Language Fashions are Few-Shot Learners. NeurIPS 2020. Github: https://github.com/openai/gpt-3
- Yang et al., Xlnet: Generalized autoregressive pretraining for language understanding. NeurIPS 2019. Github: https://github.com/zihangdai/xlnet
- Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint 2018. HuggingFace Official: https://huggingface.co/docs/transformers/en/model_doc/bert
From Masked Picture Modeling to Autoregressive Picture Modeling was initially printed in In the direction of Information Science on Medium, the place individuals are persevering with the dialog by highlighting and responding to this story.